
Vozo Rewrite & Redub 是一款创新的视频编辑工具,你可以通过简单的提示重写视频脚本、然后这个工具会自动给视频重新配音、翻译语音并口型同步,然后生成新的视频。
无论是将经典视频转变为病毒视频宣传片,还是将普通视频变成喜剧,亦或是将一种语言翻译成多种语言,Vozo 都能在几秒钟内完成。
- 视频重写与重新配音:使用AI提示重写脚本,并使用克隆的声音进行重新配音。
- 文本编辑语音:通过编辑文本更新解说,不需要重新录音。
- 多角色口型同步:视频中的多角色自然口型同步。
- 视频翻译:将视频专业翻译成30多种语言和方言。
- 自动视频重新利用:一键裁剪、重构和调整视频比例,以适应不同的社交平台。
视频重写与重新配音
使用AI驱动的提示来重写视频脚本,并使用克隆的声音进行重新配音,能够刷新旧视频,量身定制内容以适应不同的观众,并创建多语言版本。
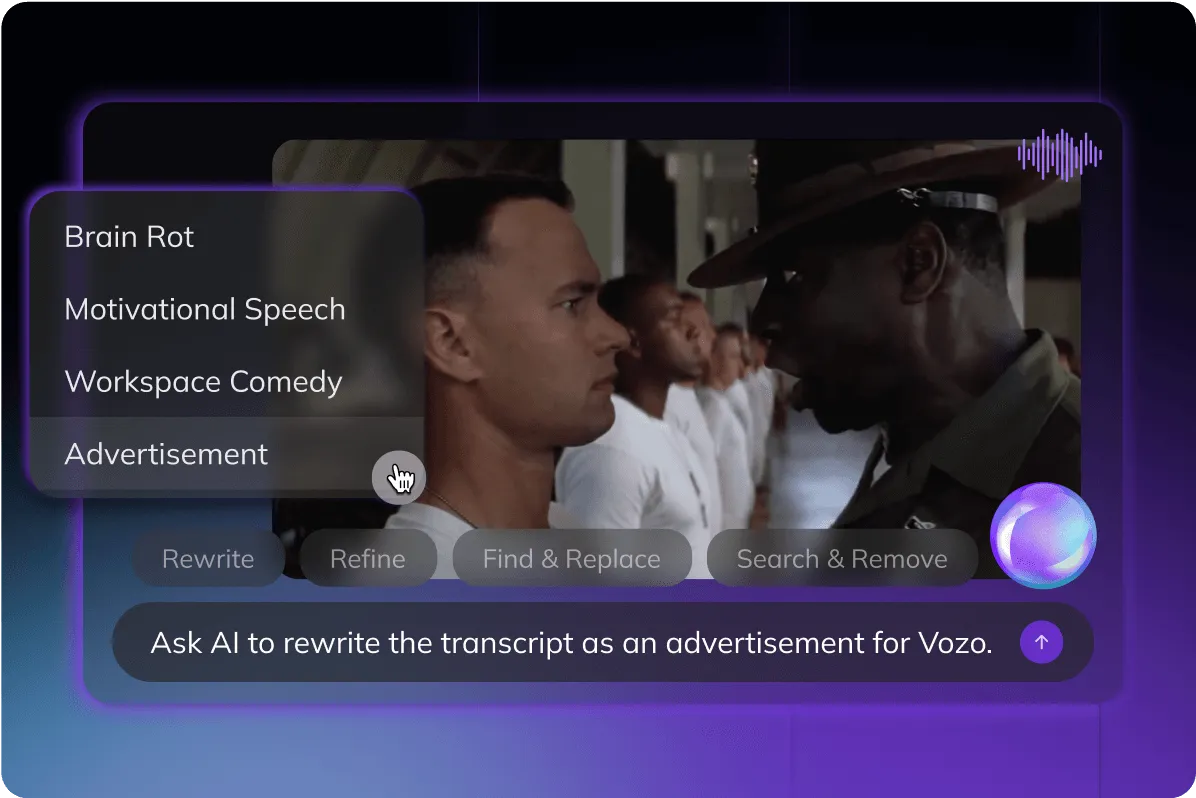 文本编辑语音
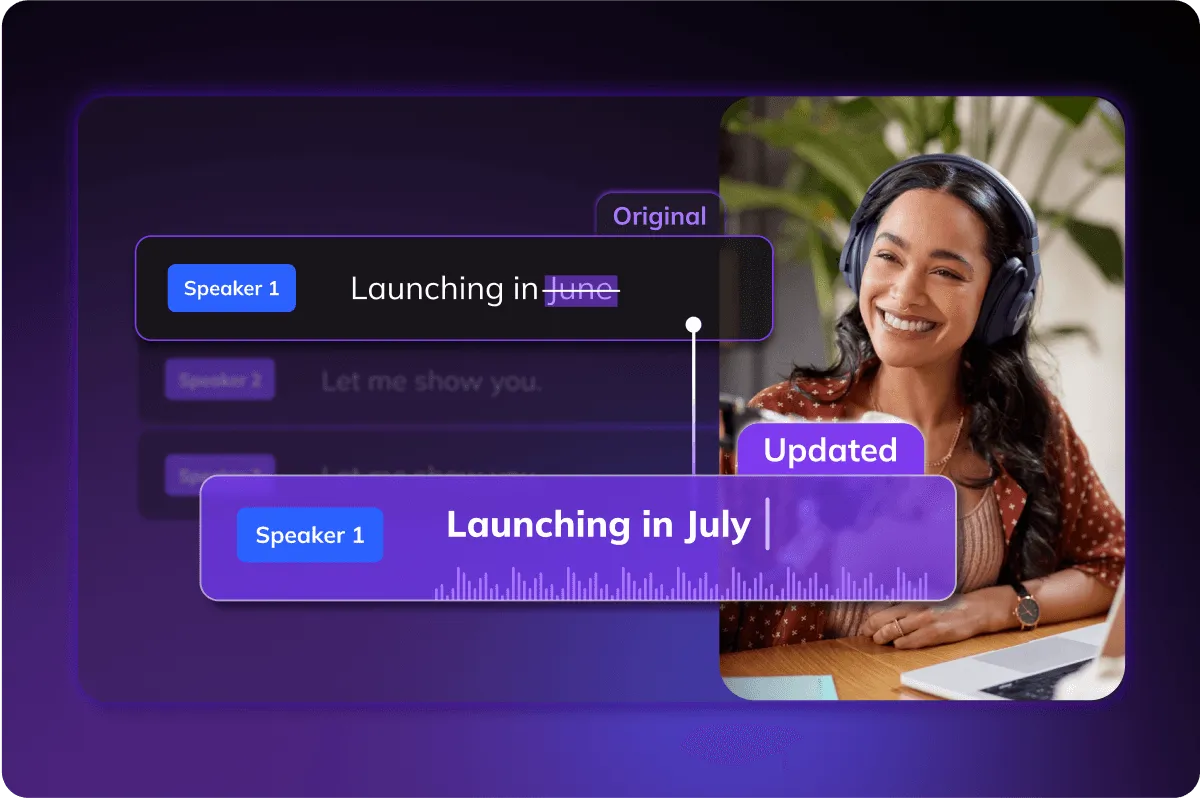
文本编辑语音
通过编辑文本来更新解说,而不需要重新录音。可以按句子更改语音,提供多种口音、语调和情感选项,使视频更加生动和吸引人。
 多角色口型同步
多角色口型同步
为视频中的多个角色进行自然的口型同步。高级技术确保口型与语音的精确匹配,提供自然和沉浸的观看体验。
 视频翻译
视频翻译
将视频专业翻译成超过30种语言和方言。提供98.9%的准确度,一键服务使内容轻松面向全球观众。
 自动视频重新利用
自动视频重新利用
一键裁剪、重构和调整视频比例,重新利用视频以适应不同的社交平台。确保内容在各种平台上格式完美、优化以获得最大互动。

使用场景
- 视频创作者:将经典片段转变为新的病毒式传播视频。
- 广告公司:修改脚本,重新配音,并口型同步广告,创建针对不同受众的无尽变体。
- 营销人员和电商:将产品视频翻译成多种语言,轻松扩大全球影响力。
- 教育者:通过编辑文本和克隆配音轻松修改教育视频,以适应任何语言或语调。














{kind=link}