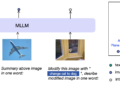
<p class="p1"><b>阿里巴巴推出QVQ-72B</b>,一个基于<b>Qwen2-VL-72B</b>的新型多模态推理模型,专注于增强视觉理解与复杂问题解决能力。</p> <p class="p1">其名称中“QVQ”代表了模型关注的<b>视觉理解(Visual understanding)和复杂推理(Reasoning)</b>。</p> <ul> <li class="p1">QVQ-72B结合了语言和视觉能力,旨在提供类似于人类专家的推理能力。</li> <li class="p1">它在视觉推理、数学和科学问题上表现出显著提升,特别是在多步推理任务中。</li> <li class="p1">在<b>MMMU</b>等测试集上获得70.3分,大幅超越Qwen2-VL-72B-Instruct。</li> <li class="p1">在数学与科学基准测试(如MathVista、OlympiadBench)中展示出优异成绩,接近当前最先进模型。</li> </ul> <h3><strong>QVQ-72B 的主要功能</strong></h3> <h5><strong>视觉理解</strong></h5> <ul> <li><strong>图片内容分析</strong>:能够从图片中提取多层次的信息,包括对象识别、场景理解、颜色、空间关系等。</li> <li><strong>细粒度视觉任务</strong>:支持解读复杂的图片内容,如图表、图像中的文字和手写体识别。</li> <li><strong>多模态上下文融合</strong>:可以结合图片和文本的语境完成更高层次的分析和理解。</li> </ul> <h5><strong> 语言理解与生成</strong></h5> <ul> <li><strong>多语言支持</strong>:对多种语言(包括中文、英语等)具有深度理解能力,适用于跨语言任务。</li> <li><strong>逐步推理</strong>:在文本任务中,采用逻辑分步推理方式,更准确地处理复杂问题,例如长链问题解答。</li> <li><strong>强大的生成能力</strong>:能够生成连贯、逻辑清晰的文本答案。</li> </ul> <h5><strong> 跨模态推理</strong></h5> <ul> <li><strong>多模态训练优化</strong> <ul> <li><strong>高质量数据训练</strong>:使用大规模多模态数据集进行训练,包括图片-文本对齐、图文描述、问答数据等。</li> <li><strong>鲁棒性强</strong>:适应各种复杂场景,如图表、自然图片、科学文本等。</li> </ul> </li> <li><strong>视觉与文本信息结合</strong>:擅长将图片信息与文本信息结合,进行复杂问题的推理和分析。 <ul> <li>示例:理解图片中的数学公式并结合问题给出答案。</li> </ul> </li> <li><strong>问题求解能力</strong>:对跨模态问题(如基于图片的推理问题)进行智能解答。</li> <li><strong>科学与数学计算</strong>:在科学、工程、数学等专业领域中具备深度推理能力。</li> </ul> <h5><strong>专业推理能力</strong></h5> <ul> <li><strong>专注于多步推理,</strong>能够以分步方式解决复杂问题: <ul> <li>在语言任务中,逐步细化解答,避免逻辑错误。</li> <li>在视觉任务中,通过递归推理层层深入,确保准确性。</li> </ul> </li> </ul> <ul> <li><strong>学术与科研</strong>:在数学、物理、化学等领域中的复杂问题求解表现出色。</li> <li><strong>逻辑推理</strong>:支持递归推理和分步推导,例如推导物理定律、解决数学奥赛题等。</li> </ul> <h3>性能表现</h3> 在 4 个数据集上评估 QVQ-72B-Preview,包括: <ul> <li>MMMU:一个大学级别的多学科多模态评测集,旨在考察模型视觉相关的综合理解和推理能力。</li> <li>MathVista:一个数学相关的视觉推理测试集,评估拼图测试图形的逻辑推理、函数图的代数推理和学术论文图形的科学推理等能力。</li> <li>MathVision:一个高质量多模态数学推理测试集,来自于真实的数学竞赛,相比于MathVista具有更多的问题多样性和学科广度。</li> <li>OlympiadBench:一个奥林匹克竞赛级别的双语多模态科学基准测试集,包含来自奥林匹克数学和物理竞赛的8,476个问题,包括中国高考。每个问题都附有专家级别的注释,详细说明了逐步推理的过程。</li> </ul> <figure><img class="aligncenter size-full wp-image-16133" src="https://img.xiaohu.ai/2024/12/QVQ-scaled.jpg" alt="" width="2560" height="996" /></figure> QVQ-72B-Preview 在 MMMU 基准测试中取得了 70.3 的分数,显著超越了 Qwen2-VL-72B-Instruct。此外,在剩下的三个专注于数学和科学问题的基准测试中,该模型表现出色,有效缩小了与领先的最先进的 o1 模型之间的差距。 <strong>多模态推理能力</strong> QVQ-72B 在整合视觉与语言信息的复杂推理任务中具有强大表现: <ul> <li><strong>视觉-语言基准测试</strong> <ul> <li><strong>MMMU (Multi-Modal Multi-task Understanding)</strong>:得分 <strong>70.3</strong>,显著超过其前代模型(如Qwen2-VL-72B-Instruct),在业界属于领先水平。</li> <li><strong>Visual Commonsense Reasoning (VCR)</strong>:擅长回答视觉常识问题,通过分析图片与文本内容实现更高的准确率。</li> </ul> </li> <li><strong>数学与科学领域</strong> <ul> <li>在 <strong>MathVista</strong> 和 <strong>OlympiadBench</strong> 等专门为测试科学推理设计的基准测试中表现优异。</li> <li>接近当前最先进的模型,特别是在数学、物理推导等多步推理任务中展现了卓越能力。</li> </ul> </li> </ul> <hr /> <h5><strong>专业领域的表现</strong></h5> <strong>数学与逻辑推理</strong> <ul> <li><strong>数学问题求解</strong> <ul> <li>在数学推理任务(如代数、微积分)中,模型通过分步推理显著减少错误率。</li> <li>能够理解并解决公式化问题,例如解析图片中的公式或数学题。</li> </ul> </li> <li><strong>多步推理</strong> <ul> <li>精通递归推理,通过分步处理复杂问题,如解答数学奥赛题或多阶段逻辑推理问题。</li> </ul> </li> </ul> <strong>科学与工程</strong> <ul> <li><strong>科学推理</strong> <ul> <li>可在物理问题中结合文字和视觉信息推导因果关系。</li> <li>在化学反应分析任务中表现卓越,例如识别图片中的化学式并解读。</li> </ul> </li> <li><strong>工程与技术图表</strong> <ul> <li>在技术报告、复杂图表分析中提取关键信息的准确率和效率较高。</li> </ul> </li> </ul> <hr /> <h5><strong>实际应用场景中的表现</strong></h5> <strong>图像识别与理解</strong> <ul> <li>精准识别图片中的细节,例如物体位置、颜色、空间关系,以及复杂情景。</li> <li>能识别手写内容、图表中的文字和数学表达式。</li> </ul> <strong>跨模态问答</strong> <ul> <li>支持复杂问题的多模态解答,结合图片和文本上下文,生成逻辑清晰的答案。</li> <li>擅长回答涉及视觉常识、数学推理等需要结合图文信息的问题。</li> </ul> <strong>语言推理</strong> <ul> <li><strong>多语言支持</strong>:支持多语言任务,包括中文、英语等,推理结果具备一致性。</li> <li>在复杂文本生成任务中,生成答案的逻辑性和连贯性均处于领先水平。</li> </ul> <hr /> <h5><strong>基准测试对比</strong></h5> <table> <thead> <tr> <th><strong>任务类别</strong></th> <th><strong>测试集</strong></th> <th><strong>QVQ-72B 得分</strong></th> <th><strong>对比优势</strong></th> </tr> </thead> <tbody> <tr> <td>多模态理解</td> <td>MMMU</td> <td>70.3</td> <td>超越前代模型,优化多模态信息融合能力</td> </tr> <tr> <td>数学推理</td> <td>MathVista</td> <td>高分,接近SOTA</td> <td>分步推理显著降低错误率,在复杂题目中表现出色</td> </tr> <tr> <td>科学问题</td> <td>OlympiadBench</td> <td>接近SOTA</td> <td>在科学领域表现优异,适合学术和科研应用</td> </tr> <tr> <td>视觉理解与推理</td> <td>VCR</td> <td>卓越表现</td> <td>在视觉常识推理任务中超越多个现有多模态模型</td> </tr> <tr> <td>图文融合问题解答</td> <td>科学/技术数据集</td> <td>高效</td> <td>对复杂技术报告和工程图表的理解能力显著提高</td> </tr> </tbody> </table> <p data-immersive-translate-walked="49e060dd-78bd-417e-8be8-9f2973653a8d">官方介绍:<a href="https://qwenlm.github.io/zh/blog/qvq-72b-preview/" target="_blank" rel="noopener">https://qwenlm.github.io/zh/blog/qvq-72b-preview/</a></p> <p data-immersive-translate-walked="49e060dd-78bd-417e-8be8-9f2973653a8d">在线演示:<a href="https://huggingface.co/spaces/Qwen/QVQ-72B-preview" target="_blank" rel="noopener">https://huggingface.co/spaces/Qwen/QVQ-72B-preview</a></p> <h3 id="示例" data-immersive-translate-walked="49e060dd-78bd-417e-8be8-9f2973653a8d">示例<a class="anchor" hidden="" href="https://qwenlm.github.io/zh/blog/qvq-72b-preview/#%E7%A4%BA%E4%BE%8B" aria-hidden="true" data-immersive-translate-walked="49e060dd-78bd-417e-8be8-9f2973653a8d">#</a></h3> <p data-immersive-translate-walked="49e060dd-78bd-417e-8be8-9f2973653a8d">以下,将展示几个示例,以说明该新模型在视觉推理任务中的应用</p> <p data-immersive-translate-walked="49e060dd-78bd-417e-8be8-9f2973653a8d"><img class="aligncenter size-full wp-image-16127" src="https://img.xiaohu.ai/2024/12/下载-22.png" alt="" width="1874" height="5902" /> <img class="aligncenter size-full wp-image-16128" src="https://img.xiaohu.ai/2024/12/下载-21.png" alt="" width="1840" height="5144" /> <img class="aligncenter size-full wp-image-16129" src="https://img.xiaohu.ai/2024/12/下载-20.png" alt="" width="1840" height="4380" /> <img class="aligncenter size-full wp-image-16130" src="https://img.xiaohu.ai/2024/12/下载-19.png" alt="" width="1824" height="8192" /> <img class="aligncenter size-full wp-image-16131" src="https://img.xiaohu.ai/2024/12/下载-18.png" alt="" width="1840" height="6572" /> <img class="aligncenter size-full wp-image-16132" src="https://img.xiaohu.ai/2024/12/下载-17.png" alt="" width="1796" height="8192" /></p>







{kind=link}