

前Stability AI 核心成员 Robin Rombach 创立了一个新的公司:“黑森林实验室”,并且获得了3200万美元的融资。
同时他们发布了一个名为Flux.1图像生成模型家族。
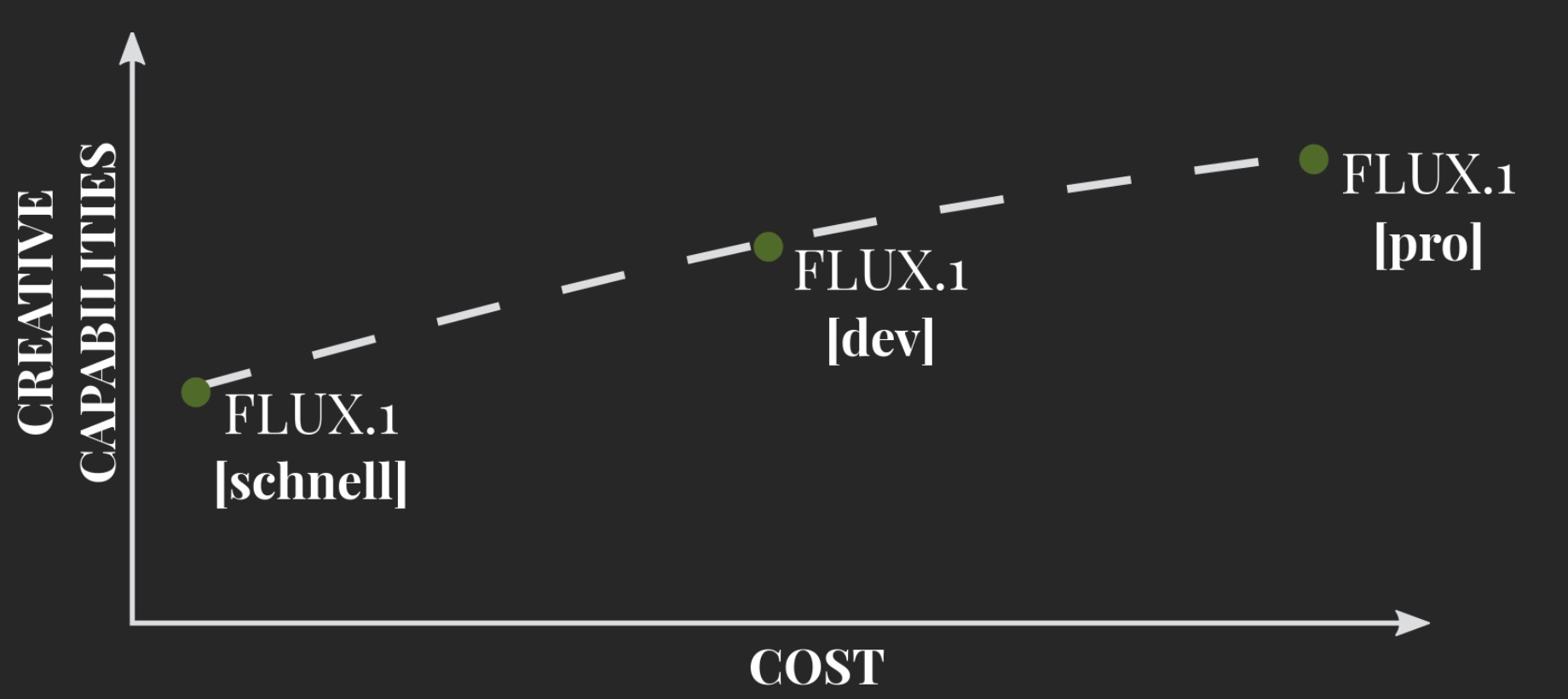
黑森林实验室(Black Forest Labs)Flux.1模型家族包含以下三个变体:
1. Flux.1 [pro]
- 描述:这是Flux.1的顶级版本,提供最先进的图像生成性能。
- 特点:
- 提示跟随:能够精确遵循用户输入的提示进行图像生成。
- 视觉质量:生成的图像具有高细节和高质量。
- 输出多样性:在不同风格和场景复杂度方面表现出色。
- 适用场景:适用于需要顶级图像生成质量的商业应用。可以通过 API 访问。
- FLUX.1 [pro] 还可以通过 Replicate 和 fal.ai 使用。
2. Flux.1 [dev]
- 描述:这是一个开源的指导蒸馏模型,适用于非商业应用。
- 特点:
- 高效性:相较于标准模型,具备更高的效率。
- 质量和提示跟随:接近于Flux.1 [pro]的质量和提示跟随能力。
- 适用场景:适用于学术研究、开发和非商业应用。模型权重可在HuggingFace上获取。
- FLUX.1 [dev] 权重在 HuggingFace 上可用,可以直接在 Replicate 或 Fal.ai 上试用。
3. Flux.1 [schnell]
- 描述:这是Flux.1模型家族中最快的模型,专为本地开发和个人使用优化。
- 特点:
- 速度优化:具备最快的生成速度。
- 开源:在Apache 2.0许可证下开放。
- 适用场景:适用于个人项目和快速原型开发。
- FLUX.1 [schnell] 在 Apache2.0 许可证下开放可用。类似于 FLUX.1 [dev],权重在 Hugging Face 上可用,推理代码可以在 GitHub 和 HuggingFace’s Diffusers 上找到。在 ComfyUI 上已经提供集成。
 Flux.1模型的技术细节
Flux.1模型的技术细节
架构设计
Flux.1模型基于一种混合架构,结合了 multimodal and parallel diffusion transformer 架构,具有以下主要特点:
- 多模态扩散变压器:支持处理文本和图像等多种模态的数据输入,提高了模型的生成能力和适应性。
- 并行扩散变压器块:通过并行处理多个扩散变压器块,加速了模型的训练和推理过程。
参数规模
- 参数数量:Flux.1模型包含12B(120亿)参数。这使得模型具有强大的学习和生成能力,能够生成高质量的图像。
关键技术创新
- 流匹配(Flow Matching):
- 描述:流匹配是一种通用且概念简单的生成模型训练方法,包括扩散作为特例。
- 优势:通过流匹配方法,模型在保持高质量生成的同时,提高了训练效率和生成速度。
- 旋转位置嵌入(Rotary Positional Embeddings):
- 描述:引入旋转位置嵌入,可以更有效地捕捉数据中的位置信息。
- 优势:提高了模型在处理不同尺寸和形状图像时的灵活性和准确性。
- 并行注意力层(Parallel Attention Layers):
- 描述:在模型中加入并行注意力层,允许模型同时关注输入数据的多个不同部分。
- 优势:显著提升了模型的计算效率和生成速度。
 性能优化
性能优化
- 硬件效率:通过结合以上技术创新,Flux.1模型在性能上进行了优化,确保了在保持高质量输出的同时,最大化硬件使用效率。
- 模型变体:
- FLUX.1 [pro]:针对商业应用,提供顶级性能和质量。
- FLUX.1 [dev]:开源版本,适用于学术和非商业应用。
- FLUX.1 [schnell]:优化速度,适用于个人开发和快速原型设计。
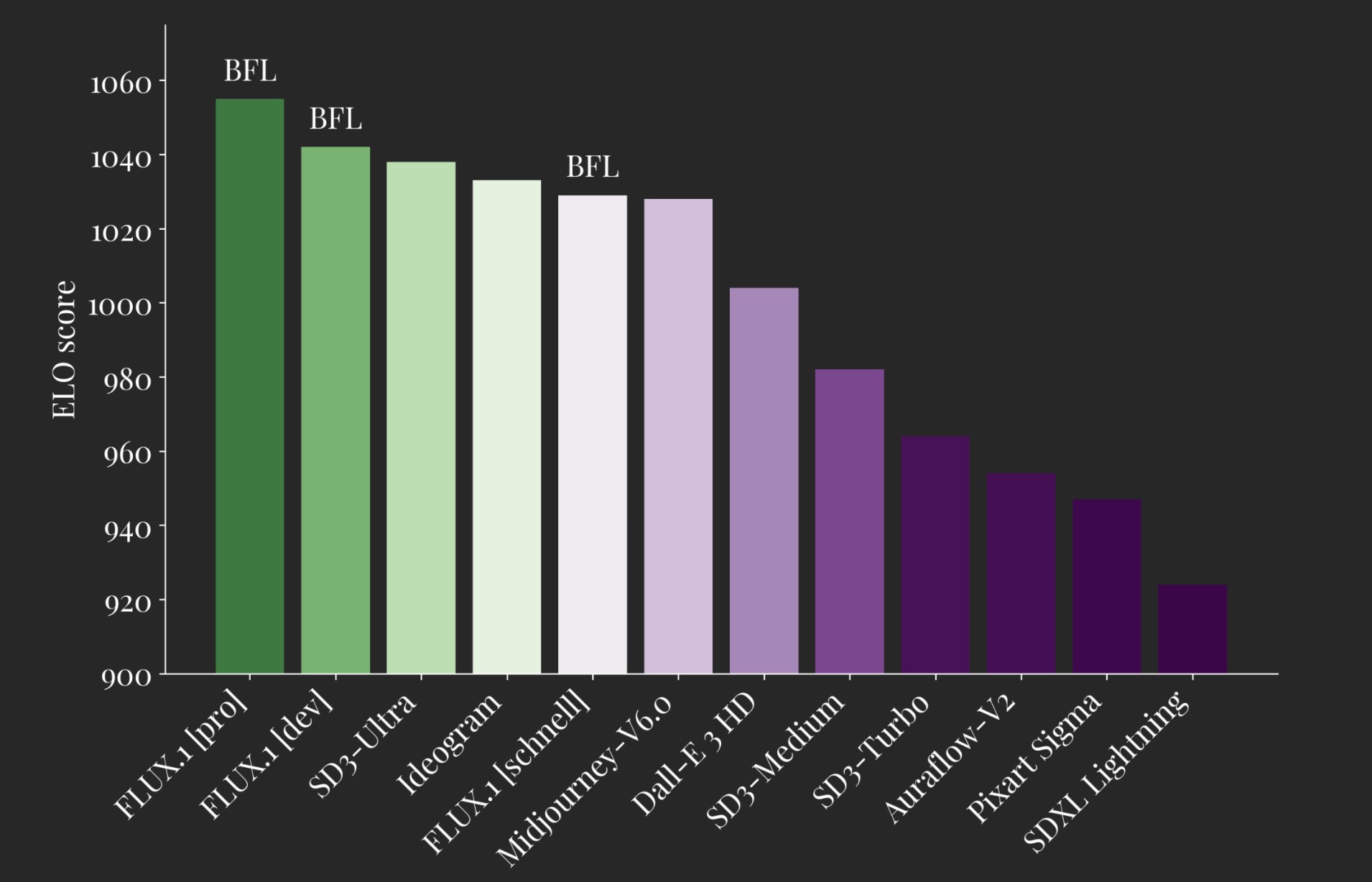
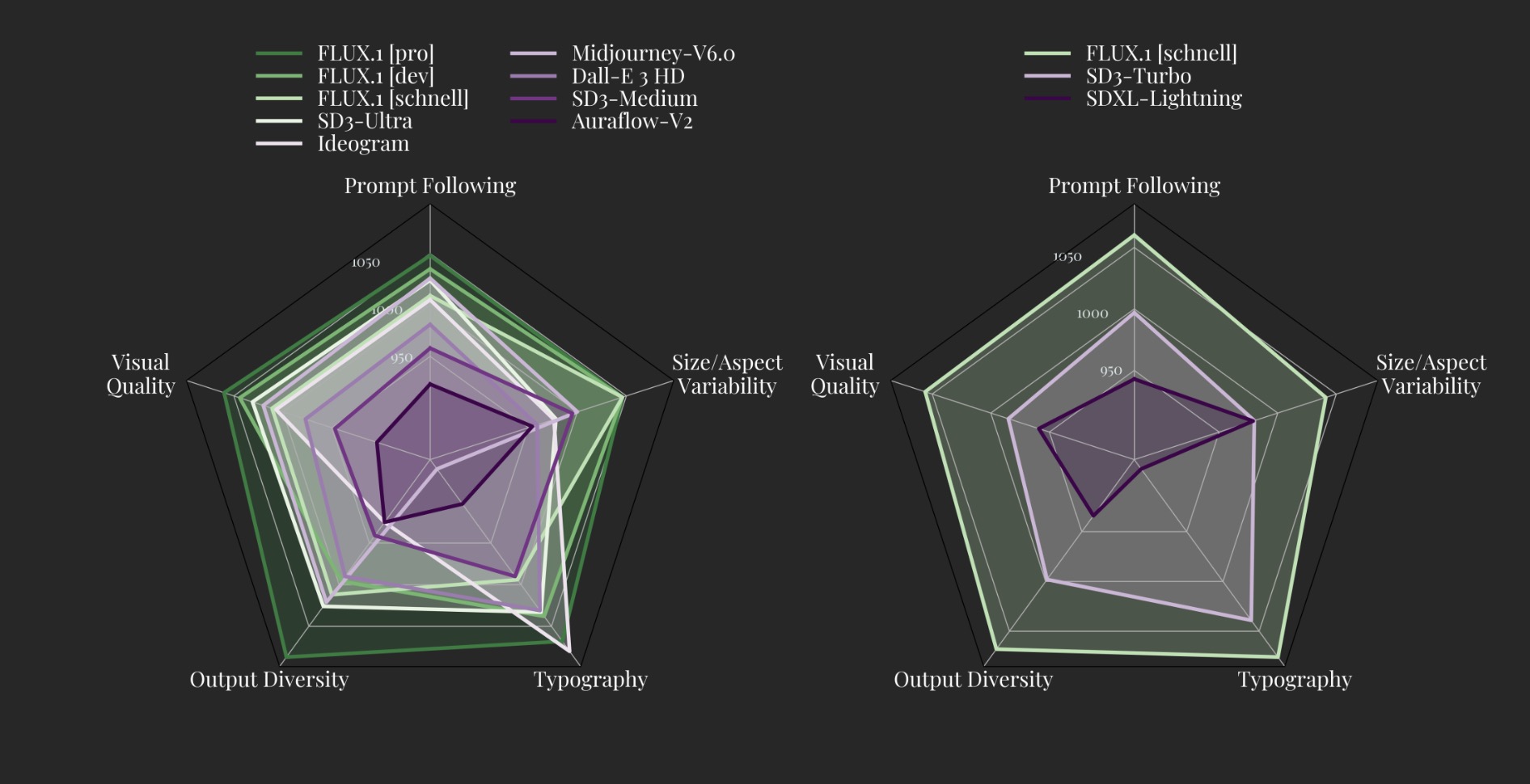
图像合成的新基准
- 视觉质量和提示跟随:Flux.1模型在视觉质量、提示跟随、大小/纵横比变化、排版和输出多样性方面,超越了Midjourney v6.0、DALL·E 3 (HD)和SD3-Ultra等流行模型。
- 输出多样性:模型经过专门微调,以保持预训练期间的全部输出多样性,提供更丰富和多样化的生成结果。
所有 FLUX.1 型号都支持不同的长宽比和分辨率(10 万和 200 万像素),如下图所示。

实际应用
- 多样化的应用场景:从商业图像生成到个人项目开发,Flux.1模型提供了广泛的应用可能性。
- 开放平台和资源:FLUX.1 [dev]和FLUX.1 [schnell]模型的权重和推理代码在HuggingFace和GitHub上公开,方便开发者使用和二次开发。
同时FLUX.1 文本到图像模型套件,为他们即将推出的竞争性生成 文本到视频系统 奠定了坚实基础。官方称他们的视频模型将以高清晰度和前所未有的速度实现精确创作和编辑。
核心团队
- 创始人及领导者
- 杰夫·迪恩(Jeff Dean):作为团队的领导者,杰夫在机器学习和生成式AI领域具有丰富的经验和深厚的知识。他在Google DeepMind担任高级研究员,并领导了多个关键项目的研发。
- 主要研究人员
- 维克多·伊拉斯塔(Victor Irastorza):在生成模型架构设计和算法优化方面具有深厚的研究背景,曾在多家顶尖研究机构任职。
- 艾玛·金(Emma King):专注于多模态学习和图像生成技术,发表了多篇重要论文,并在学术界和工业界获得了广泛认可。
- 艾里克·斯通(Eric Stone):在深度学习和模型压缩方面具有丰富的经验,致力于提升模型的计算效率和生成质量。
- 工程团队
- 卡拉·李(Cara Lee):负责模型的工程实现和优化,确保模型在不同硬件平台上的高效运行。
- 雷恩·托马斯(Ryan Thomas):专注于大规模数据处理和模型训练管道的开发,提升了模型的训练速度和稳定性。
贡献与成就
- 包括创建 VQGAN 和 Latent Diffusion,用于图像和视频生成的 Stable Diffusion 模型(Stable Diffusion XL,Stable Video Diffusion,Rectified Flow Transformers),以及用于超快实时图像合成的 Adversarial Diffusion Distillation。
融资与支持
- 主要投资者:安德森·霍洛维茨(Andreessen Horowitz)领投,天使投资人布伦丹·伊里比(Brendan Iribe)、迈克尔·奥维茨(Michael Ovitz)、加里·谭(Garry Tan)、提莫·艾拉(Timo Aila)和弗拉德伦·科尔顿(Vladlen Koltun)等知名专家参与。
- 后续投资:General Catalyst和MätchVC提供的后续投资,支持团队实现将最先进AI技术从欧洲带给全球用户的使命。
演示效果:
示例1
Style: portrait
风格:肖像Prompt: Create a captivating portrait of a voluptuous boho woman with green eyes and long, wavy blonde hair, she is standing. She has a fair complexion adorned with delicate freckles, and her expression is contemplative, reflecting a moment of deep thought. She wears a white-colored, off-shoulder linen satin dress, with deep neck linen, complemented by a necklace and various boho jewelry that accentuates her bohemian style., photo, poster, vibrant, portrait photography, fashion
提示:创作一幅迷人的肖像画,画中人物是一位拥有绿色眼睛和金色波浪长发的丰满波西米亚女性,她站立着。她肤色白皙,脸上有细腻的雀斑,表情沉思,反映出深思的瞬间。她身着白色露肩亚麻缎面连衣裙,深领亚麻面料,配以项链和各种波西米亚风格首饰,更显其波西米亚风格。

示例2
Style: surreal
风格: 超现实Prompt: pareidolic anamorphosis of a hole in a brick wall morphed into a hublot of a sail boat, a window to the sea.
提示:砖墙上的一个洞蜕变成一艘帆船,一扇通向大海的窗户。

示例3
Style: photo
风格:photoPrompt: a cat sit near the bech with sun glass, photo.
提示:一只猫坐在有阳光玻璃的贝壳附近,照片。

示例4
Style: satirical
风格: 讽刺Prompt: Circus tent made out of a worn us flay with text that says not my circus not my clowns. With Biden and trump dressed as clowns in a suit made of the us flag.
提示:用破旧的美国国旗做成的马戏团帐篷,上面写着不是我的马戏团,不是我的小丑。拜登和特朗普穿着美国国旗制成的衣服,扮成小丑。

模型下载:https://huggingface.co/black-forest-labs
GitHub:https://github.com/black-forest-labs/flux
在线体验:https://flux1.ai/
Replicate: :
- https://replicate.com/collections/flux
- https://replicate.com/black-forest-labs/flux-pro
- https://replicate.com/black-forest-labs/flux-dev
- https://replicate.com/black-forest-labs/flux-schnell
FAL: :
- https://fal.ai/models/fal-ai/flux-pro
- https://fal.ai/models/fal-ai/flux/dev
- https://fal.ai/models/fal-ai/flux/schnell
ComfyUI:https://github.com/ZHO-ZHO-ZHO/ComfyUI-Workflows-ZHO
官方介绍:https://blackforestlabs.ai/announcing-black-forest-labs/













{kind=link}