
OpenAI 发布了GPT-4-Turbo 正式版
带有视觉能力,上下文 128k
主要信息包括:
▶ 全面开放,可通过“gpt-4-turbo”来使用此模型,最新版本为“gpt-4-turbo-2024-04-09”
▶ 基础能力更新,按官方说法:Majorly improved GPT-4 Turbo model
▶ 自带视觉能力,无需使用 4v 接口
▶ 128k 上下文
▶ Vision 请求现在也可以使用 JSON 模式和函数调用。
▶ 训练数据截止至 2023 年 12 月
这里查阅接口信息:https://platform.openai.com/docs/models/gpt-4-turbo-and-gpt-4
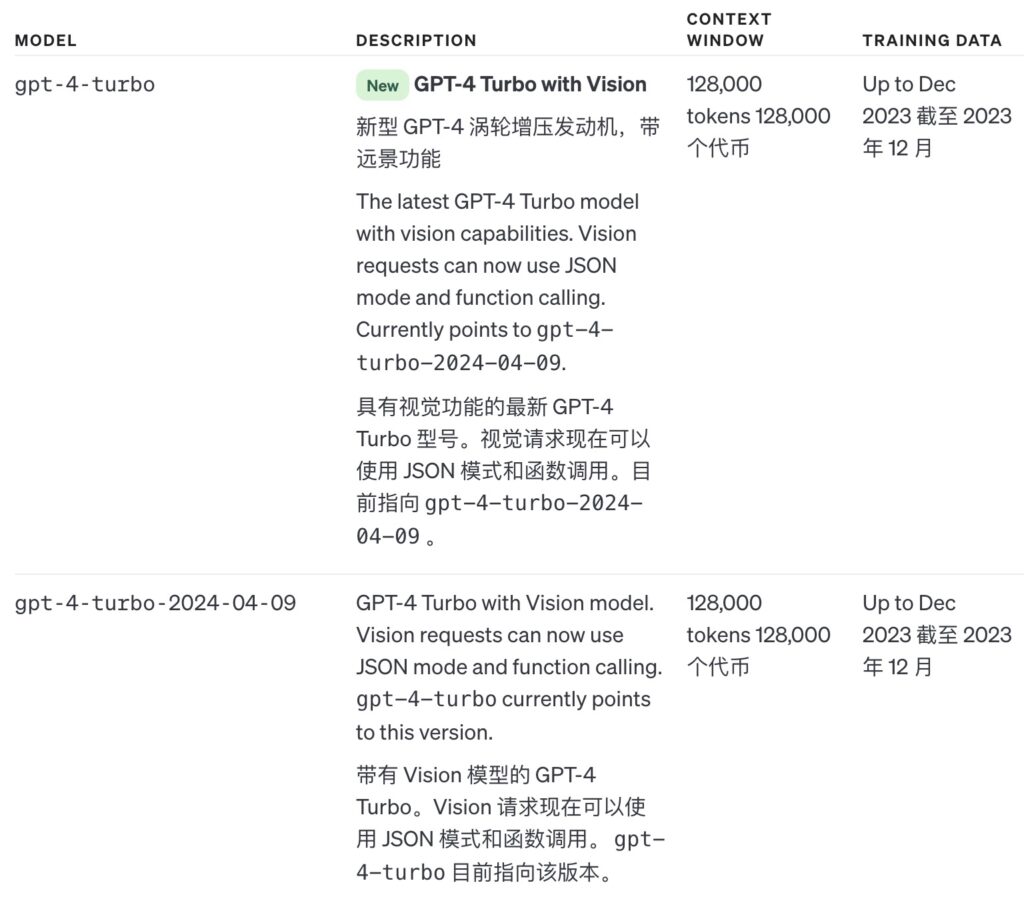
价格方面,和之前的 GPT-4-Turbo 保持一致,即:
▶ 输入:$10.00 / 100万 tokens
▶ 输出:$30.00 / 100万 tokens
▶ 读图:最低 $0.00085 / 图
这里查阅价格信息:https://openai.com/pricing
频率限制方面,以最高级 Tire 5 为例,官方说明中:
▶ 最高并发:10,000 次/ 分钟
▶ 最高处理:1,500,000 tokens / 分钟
这里查阅相关限制:https://platform.openai.com/docs/guides/rate-limits/usage-tiers?context=tier-five
GPT-4-Turbo 视觉能力应用案例
OpenAI 还展示了几个使用GPT-4-Turbo 带有视图能力的案例:
1、Devin 由@cognition_labs 构建,是一个由 GPT-4 Turbo 提供支持的 AI 软件工程助手,可使用视觉执行各种编码任务。
2、@healthifyme 团队使用带有 Vision 的 GPT-4 Turbo 构建了 Snap,可以识别世界各地的各种食物照片,为用户提供营养见解。
3、由 @tldraw 开发的 Make Real 让用户可以在白板上绘制 UI,并使用带有 Vision 的 GPT-4 Turbo 直接生成代码设计网站。














{kind=link}