

Video2Game :它能将单个视频转换成可以实时互动的、逼真的游戏和模拟环境。该项目由伊利诺伊大学香槟分校和上海交通大学的研究人员开发。
它通过神经网络技术(NeRF)捕捉场景的详细视觉和几何信息,并将这些信息转化为游戏中的网格模型和物理行为,使得虚拟环境不仅逼真,还可以实时互动。玩家可以在这些环境中行走、驾车、甚至与场景中的对象互动,如射击和碰撞,所有这些都遵循现实世界的物理法则。此外,这项技术还可以用于机器人模拟,例如使用机器人在虚拟环境中操控物体。
项目主要通过使用先进的计算机视觉和机器学习技术,例如神经辐射场(NeRF),来捕捉视频中场景的详细视觉和几何信息。通过这种方式,Video2Game 创造出数字化、可交互的虚拟环境,这些环境不仅视觉逼真,还可以实时响应用户的操作和控制。
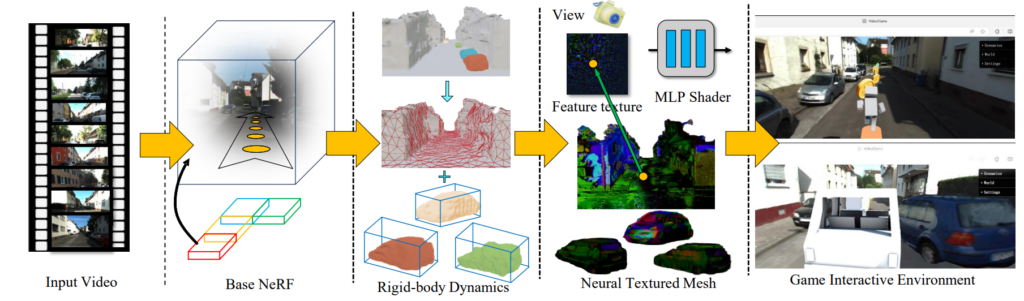
该系统的核心由三个主要组件构成:
-
神经辐射场(NeRF)模块:有效捕捉场景的几何形态和视觉外观
- 功能:通过构建复杂的三维模型来捕捉视频中场景的深度和细节,包括光影和纹理。
- 应用:这一模块能够生成非常逼真的场景渲染效果,为后续的互动和模拟提供基础。
-
网格模块:从 NeRF 中提取知识以实现更快的渲染
- 功能:将从 NeRF 模型中得到的数据转化为网格数据,这些网格数据更适合于快速渲染和实时处理。
- 应用:使得虚拟环境在保持视觉效果的同时,渲染速度更快,适应实时游戏和交互需求。
-
物理模块:模拟对象间的交互和物理动力学
- 功能:为每个物体建立物理属性,如重力、碰撞模型和动力学行为,模拟真实世界的物理规律。
- 应用:玩家与环境中的对象互动(如推动、撞击、抛掷等)时,所有动作都符合物理法则,增强游戏的真实感和沉浸感。
通过精心设计的流程,可以构建一个可交互的、可行动的数字复制品,适用于室内外大规模场景。
Video2Game 的功能
-
逼真的虚拟环境生成:
- 利用 NeRF 技术从视频中重建高质量的三维场景,包括场景的几何形状和外观。
-
快速渲染与交互:
- 通过从 NeRF 提取的数据创建网格模型,加速渲染过程,同时保持视觉效果的逼真。
- 加入物理模块,模拟对象之间的交互和动力学,使环境能够响应玩家的操作。
-
多样的游戏玩法:
- 导航与探索:玩家可以在精细重建的虚拟环境中自由移动和探索,体验与真实世界相仿的视觉和物理效果。
- 物理交互游戏:例如射击、推动或破坏场景中的对象,如足球撞击瓶子等。
- 收集与赛车:在城市环境中收集物品或进行赛车游戏。
-
机器人模拟:
- 利用构建的环境测试和模拟不同的机器人行为,如抓取、移动或推动物体。
- 使用机器人进行复杂的交互操作,如精确控制机械臂进行物体搬运。
技术流程
-
输入视频处理:
- 功能:捕获和分析输入视频,提取必要的视觉和几何信息,这是环境建模的基础。
- 实现方式:首先,从输入的视频中提取关键帧,然后使用图像处理技术和机器学习方法分析这些帧,以便识别和提取场景的结构和动态信息。
-
场景重建与NeRF建模:
- 功能:使用神经辐射场(NeRF)技术重建视频中的3D场景。
- 实现方式:通过NeRF模型对提取的关键帧进行深度学习训练,学习场景的3D结构和视觉细节。这包括学习场景中每个位置的颜色和透明度,从而能在任何新的视点下重建场景的视觉外观。
-
网格转换与优化:
- 功能:将NeRF的输出转换为游戏引擎可以更高效处理的网格格式。
- 实现方式:使用行走立方体算法从NeRF模型中生成网格,然后对这些网格进行优化,如简化几何复杂度、优化纹理映射等,以确保在游戏引擎中的高效渲染。
-
物理和互动模拟:
- 功能:为重建的场景添加物理属性和互动能力。
- 实现方式:定义网格的碰撞体,赋予物理参数(如质量、摩擦力和反弹力),并在游戏引擎中集成物理引擎(如Cannon.js),以模拟真实的物理交互效果。
-
游戏引擎集成:
- 功能:将优化后的网格和模拟的物理环境整合到一个实时游戏引擎中。
- 实现方式:利用WebGL和其他现代游戏开发框架,如Three.js或Unity,将处理后的场景、纹理、物理属性及行为逻辑集成到交互式的游戏或模拟器中。
-
用户交互界面:
- 功能:提供用户与虚拟环境互动的界面。
- 实现方式:开发直观的用户控制和反馈系统,允许玩家使用键盘、鼠标或其他输入设备来控制视角、移动和与环境中的对象互动。
功能和演示
-
导航互动(Gardenvase场景):
- 功能:在虚拟环境中,代理(游戏中的角色)可以自由地导航,探索复杂的虚拟场景。
- 物理规则遵循:所有动作,包括角色移动和与环境交互,都严格遵守现实世界的物理法则。
- 交互性:角色可以在虚拟环境中自由导航,他们的行动遵循真实世界的物理规律,并受到碰撞模型的限制。此外,玩家还可以与额外插入的物体(如足球)进行互动,这一切都遵循物理规律。
-
射击动作(Gardenvase场景):
- 功能:玩家可以执行射击动作,目标是场景中的中央花瓶。
- 实现细节:使用刚体碰撞动力学模拟射击影响,花瓶使用盒形碰撞体,背景使用凸多边形碰撞体。
- 效果:玩家用球形碰撞体射击花瓶,使其从桌子上飞起并坠落。
-
收集硬币(KITTI-360场景):
- 功能:代理在KITTI-360环境的四条街道上收集硬币,模拟类似“庙堂逃亡”游戏的活动。
- 交互性:此活动要求高度动态交互和对环境的敏感反应。
-
椅子破碎效果(KITTI-360场景):
- 功能:道路上的椅子可以被破坏,展示了物理碰撞和破坏的效果。
- 实现细节:使用预计算的破碎动画来实现视觉上的破坏效果,增加游戏的真实感和互动性。
Related Posts















{kind=link}