

Seed-Music是一个由字节跳动研发的音乐生成模型,用户可以通过输入多模态数据(如文本描述、音频参考、乐谱、声音提示等)来生成音乐,并且提供了方便的后期编辑功能,比如修改歌词或旋律。
Seed-Music 结合了自回归语言模型和扩散模型,在保持音乐生成质量的同时,提供了对生成音乐的精确控制。
Seed-Music还支持用户上传短暂的语音片段,系统会将其转换为完整的歌声。
此外,Seed-Music不仅支持声乐和器乐生成,还支持歌声合成、歌声转换、音乐编辑等功能,适用于不同的用户群体。
主要功能
- 高质量音乐生成:支持生成声乐和器乐作品,用户可以通过文本、音频等多种方式输入,实现多样化的音乐创作。
- 受控音乐生成:提供细粒度的音乐控制,允许用户根据歌词、风格描述、参考音频、乐谱等生成符合要求的音乐。
- 多模态输入:Seed-Music 支持多种输入方式,如歌词、音乐风格描述、参考音频、乐谱、语音提示等,从而实现细粒度的控制。
- 风格控制:用户可以通过文本或音频参考,指定音乐的风格、节奏、曲调等,生成符合需求的作品。
- 歌声合成与转换:
- 歌声合成:生成自然且富有表现力的歌声,支持多语言。
- 零样本歌声转换:只需10秒的语音或歌声录音,即可将其转换为不同风格的音乐。
- 歌词转歌曲 (Lyrics2Song):将输入的歌词转化为带有伴奏的声乐音乐,支持短篇和长篇音乐生成。
- 音频提示和风格转换:支持音频延续和风格转换,基于已有音频生成相似风格的新音乐。
- 器乐生成:生成高质量的纯器乐音乐,适用于无歌词的场景。
- 音乐后期编辑:支持歌词、旋律的修改,允许用户在生成的音频上直接进行编辑和调整。
- 歌词与旋律编辑:Seed-Music 提供了交互式的工具,允许用户在生成的音频中直接编辑歌词和旋律,方便进行后期调整。
- 音乐混音与编曲:系统不仅能生成完整的歌曲,还支持对生成的歌曲进行修改,如调整乐器部分、混音效果等。
- 多风格与多语言支持:Seed-Music 能够生成涵盖多种音乐风格(如流行、古典、爵士、电子等)的作品,并支持多语言歌声生成,使其适用于全球用户。
- 实时生成与流媒体支持:支持实时音乐生成和流媒体输出,提升用户的互动性和创作效率。
架构概述
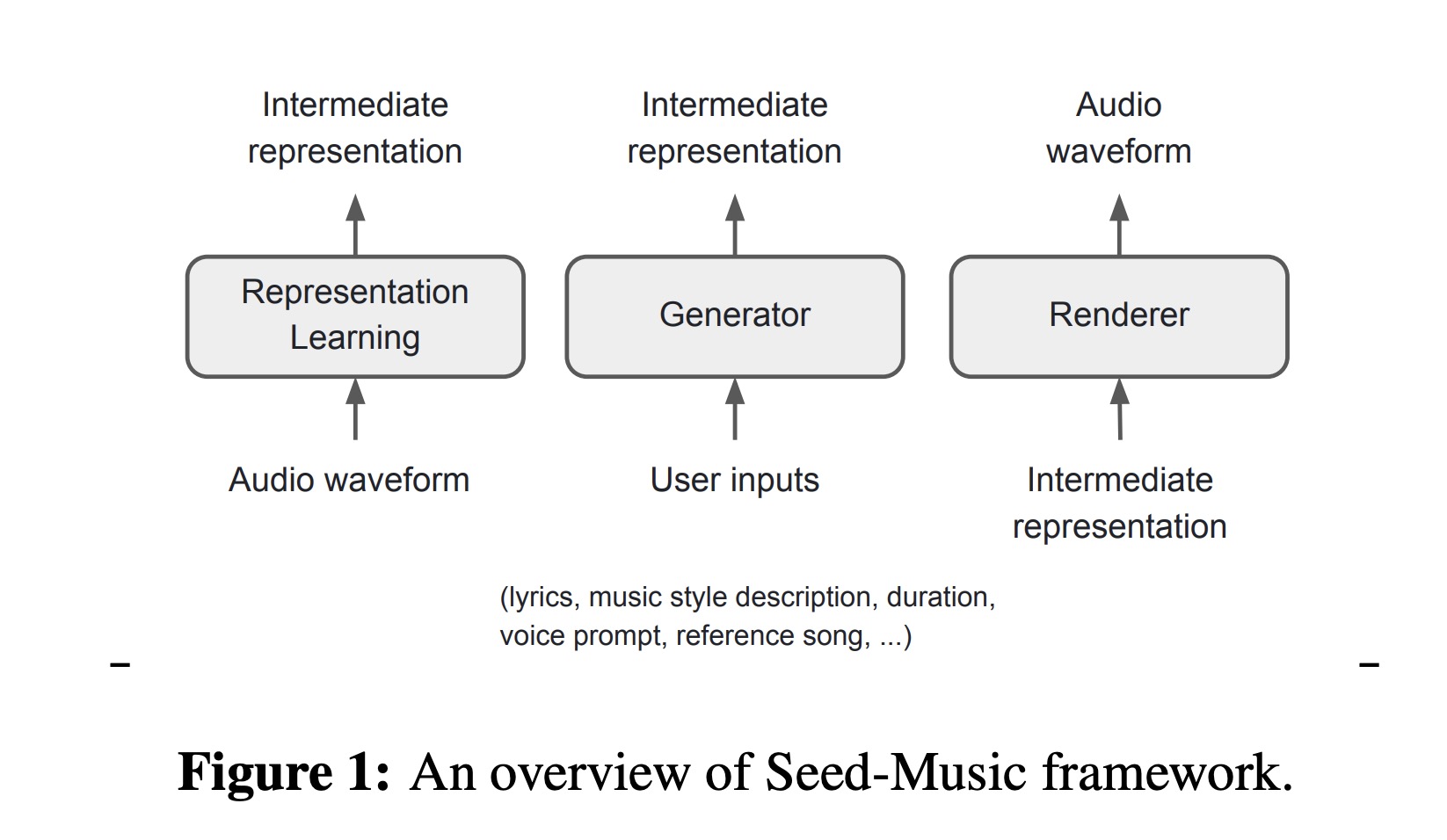
Seed-Music的架构由三大模块组成:表示学习模块、生成模块和渲染模块。这些模块协同工作,通过多模态输入(如文本、音频、乐谱等)生成高质量的音乐。
- 表示学习模块:将原始音频信号压缩为三种中间表示(音频符号、符号音乐标记和声码器潜在表示),每种表示适用于不同的音乐生成和编辑任务。
- 生成模块:通过自回归语言模型和扩散模型,基于用户的多模态输入生成相应的音乐表示。
- 渲染模块:将生成的中间表示转化为高质量的音频波形,使用扩散模型和声码器渲染最终的音频输出。
 技术方法
技术方法
Seed-Music采用了多种生成技术,确保系统能够灵活应对不同的音乐生成和编辑需求:
- 自回归语言模型 (Auto-Regressive Model):基于用户输入(如歌词、风格描述、音频参考等),逐步生成音频符号。此方法适用于需要强语境依赖的音乐生成任务,如歌词生成和风格控制。这个技术可以一步步生成音乐符号,就像根据一段歌词逐字逐句写出一首歌。它能很好地控制音乐的节奏、旋律和歌词的匹配。
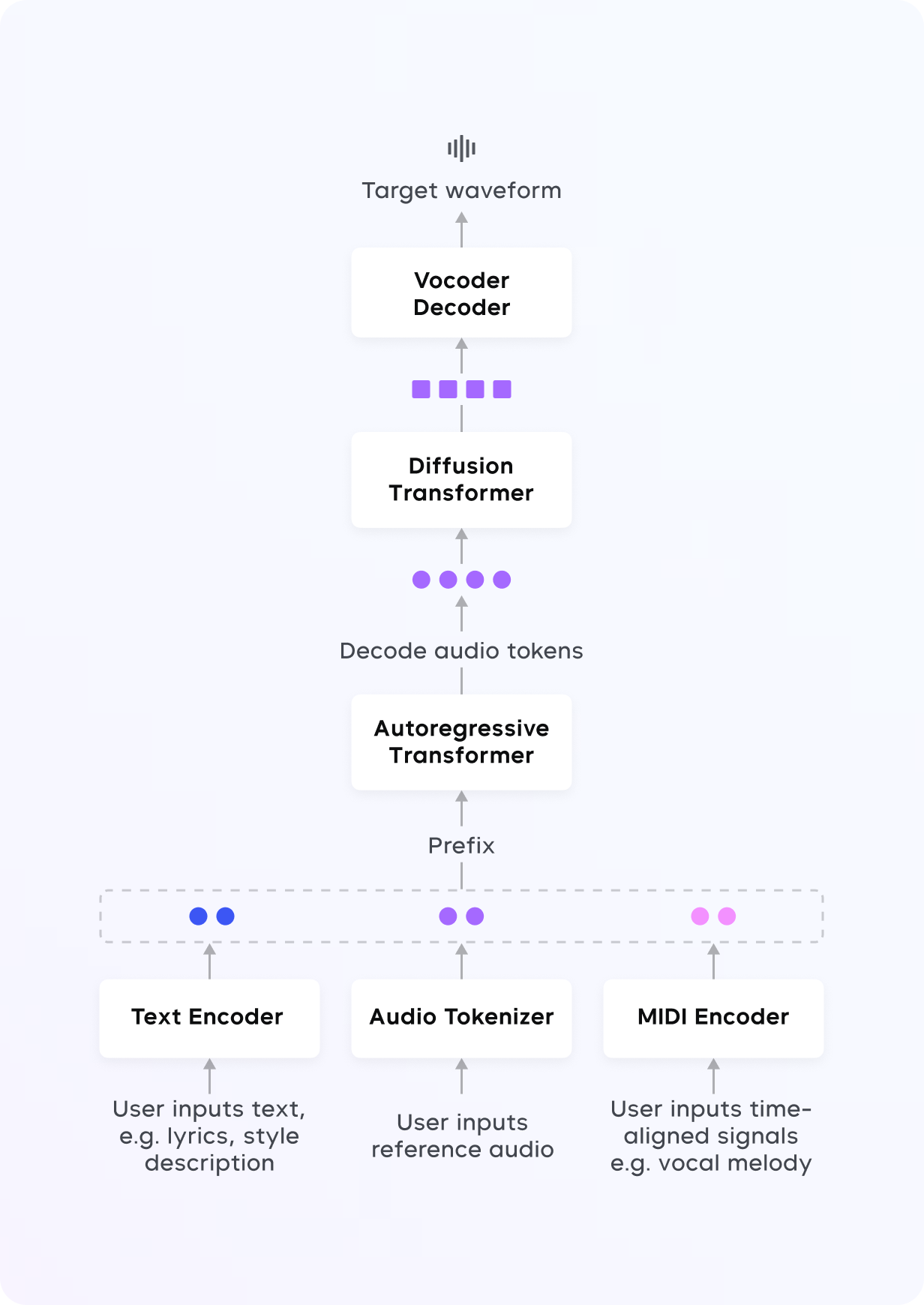
- 扩散模型 (Diffusion Model):适用于复杂的音乐生成和编辑任务,能够通过逐步去噪生成清晰的音乐表示。扩散模型非常适合需要多步预测和高保真度的任务,如精细的音频编辑。它通过把复杂的音频逐渐“打磨”成清晰的音乐,非常适合后期编辑或调整音乐的细节。
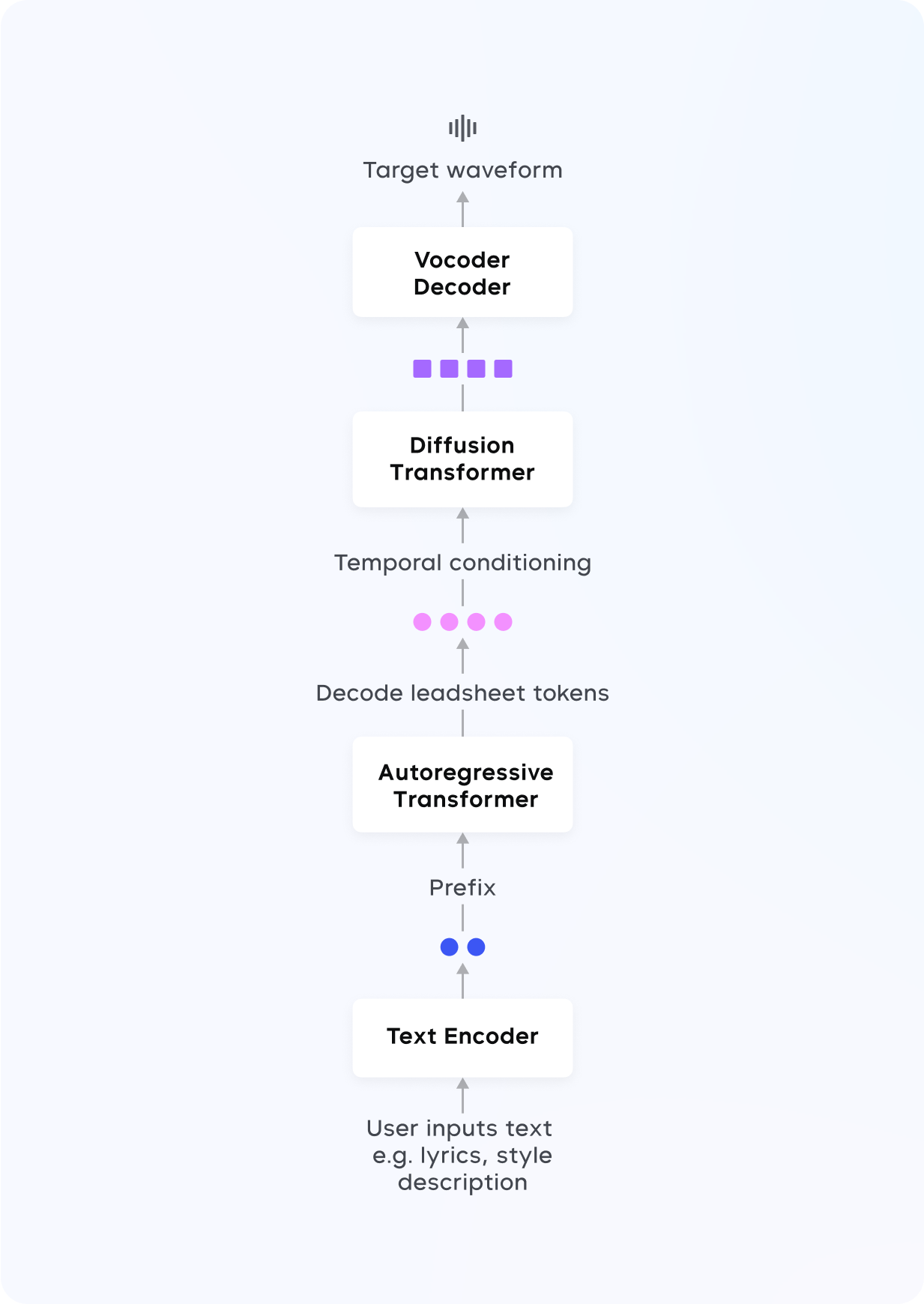
- 声码器 (Vocoder):类似于把“音乐代码”翻译成高质量的声音文件,生成可以直接播放的音乐。负责将生成的表示转换为最终的高质量音频。通过变分自编码器 (VAE) 技术,声码器可以生成44.1kHz的高保真立体声。
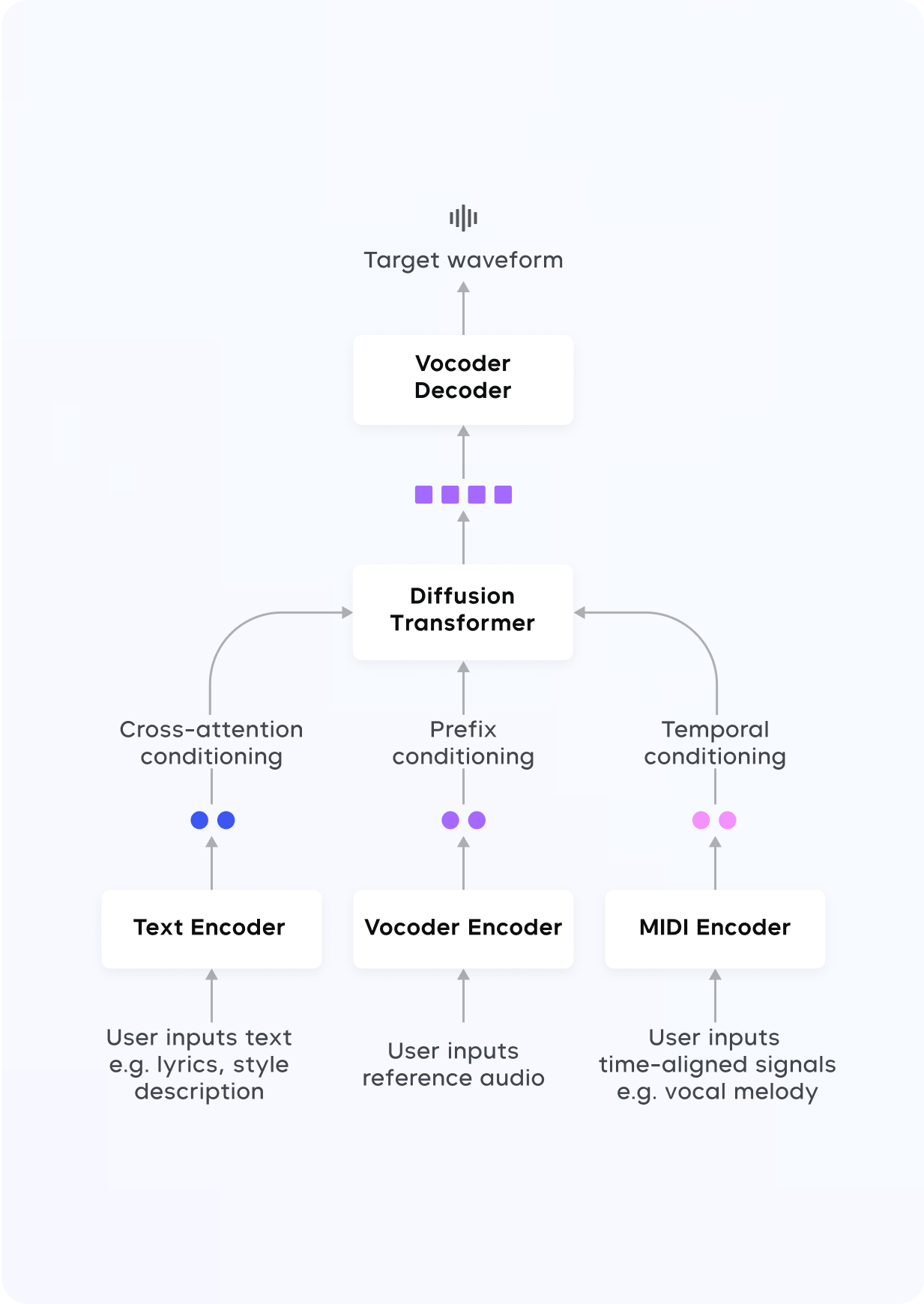
中间表示
Seed-Music采用三种不同的中间表示,分别用于不同的生成任务:
- 音频符号 (Audio Tokens):用于编码旋律、节奏、和声等音乐特征,适合自回归模型。包含音乐的旋律、节奏等信息,适合生成具体的音乐片段。
- 符号音乐标记 (Symbolic Music Tokens):像乐谱一样,用来表示音乐的旋律和和弦,可以用于乐谱生成和编辑。如MIDI,适用于乐谱生成与编辑任务,提供可读、可编辑的音乐表示。
- 声码器潜在表示 (Vocoder Latents):处理更复杂的声音细节,适合精细编辑和生成复杂的音乐作品。适用于扩散模型的生成和编辑任务。
训练与推理
Seed-Music 的模型训练分为三个阶段:预训练、微调和后训练:
- 预训练:通过大规模的音乐数据预训练模型,建立生成音乐的基础能力。
- 微调:通过特定的任务或数据微调模型,提升模型在具体生成任务中的表现,例如提高音乐性、生成准确度等。
- 后训练(强化学习):通过强化学习优化生成结果的可控性和音乐质量,使用奖励模型如歌词与音频匹配度、音乐结构一致性等来优化输出质量。
推理时,Seed-Music 使用流媒体生成技术,使用户能够实时体验生成过程,并根据实时生成的内容进行反馈和调整。















{kind=link}