
Stability AI宣布推出Stable Audio 2.0,这是一个新型模型,能从单一的自然语言提示生成高质量、具有连贯音乐结构的完整音轨,最长可达三分钟,音质为44.1 kHz立体声。与之前的版本相比,Stable Audio 2.0不仅支持文本到音频的转换,还新增了音频到音频的功能,允许用户上传音频样本并将其转换为各种声音。这一更新还扩展了声效生成和风格转换功能,提供了更大的灵活性、控制权。
新模型的特点
-
高质量全长音轨生成: 能够从单一的自然语言提示生成最长达三分钟的完整音轨,音质为44.1 kHz立体声。这些音轨具有连贯的音乐结构,包括引言、发展、高潮和结尾,提供了完整的音乐体验。
举例:假设一位音乐制作人想要创作一首电子舞曲,但目前只有一个大致的概念。通过使用Stable Audio 2.0,他可以输入一个描述性的自然语言提示,比如“创作一首充满活力的电子舞曲,带有鼓点、合成器旋律,适合夜晚派对氛围”。Stable Audio 2.0将基于这个提示,自动生成一首最长三分钟的完整电子舞曲,这首曲子将包含一个引言部分,用于吸引听众的注意;一个发展部分,展现曲子的主旋律和节奏;以及一个结尾部分,为整首歌曲画上完美的句号。整个过程还会包括高质量的立体声声效,使得生成的音轨听起来更加丰富和专业。
-
音频到音频转换能力: 新增的音频到音频功能允许用户上传音频样本,并通过自然语言提示将这些样本转换成各种声音。这为用户创造独特音效提供了更大的灵活性。
举例:考虑到一位游戏开发者需要为其即将发布的城市探险游戏制作背景音乐和环境声效。通过Stable Audio 2.0,开发者能上传一些基础的城市环境声样本,比如汽车鸣笛声、人群交谈声等,然后使用自然语言提示来指导模型转换这些样本为游戏中需要的各种声效,如增强的街道嗡嗡声、下雨声或是特定场景下的人群欢呼声,从而为游戏提供了更加生动和真实的听觉体验。
-
声效生成与风格转换: Stable Audio 2.0能够产生丰富的声音和音频效果,从键盘轻敲声到人群欢呼声或城市街道的嗡嗡声。此外,它还提供了风格转换功能,能够无缝地修改新生成或上传的音频以符合项目的特定风格和调性。
举例:假设一位电影导演正在寻找特定风格的音乐来配合其电影的某个场景,该场景是在一个古老的、神秘的森林中。导演可以将一段已有的音乐上传至Stable Audio 2.0,并使用风格转换功能,通过输入提示如“将这段音乐转换为更加古老和神秘的森林风格”,模型便能自动调整上传音乐的风格,使其与电影场景的氛围和调性完美匹配。
用户现在还可以上传音频样本,并通过自然语言提示将这些样本转换成各种声音
技术方法
Stable Audio 2.0 使用了一系列先进的技术方法来实现其创新的音乐生成能力,主要包括:
潜在扩散技术
- 高度压缩的自编码器:这种自编码器能将原始音频波形压缩成更短的表示形式。它捕获并再现音频的核心特征,同时过滤掉不那么重要的细节,从而生成更连贯的音乐作品。
- 扩散变换器(DiT):扩散变换器逐步将随机噪声精炼成结构化数据,识别复杂的模式和关系。结合高度压缩的自编码器,DiT能够处理更长的序列,从输入中创建更深入、更精确的解释。
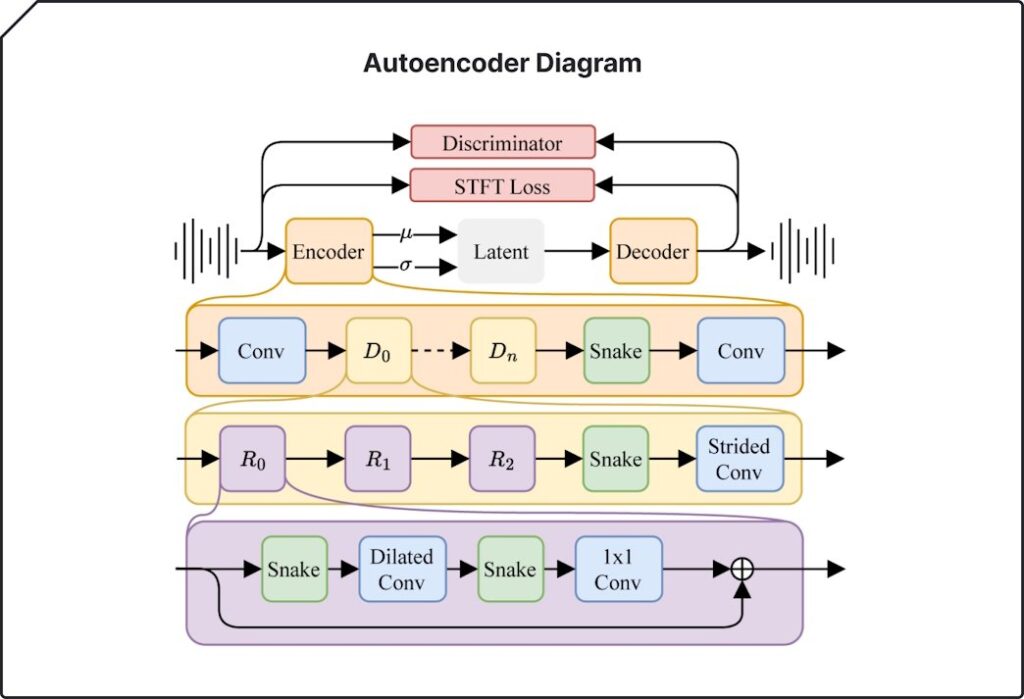
技术架构
Stable Audio 2.0的技术架构被专门设计来生成具有连贯结构的全长音轨。通过对系统的所有组件进行改进,提高了模型在长时间尺度上的性能。模型的两大关键技术——高度压缩的自编码器和扩散变换器(DiT),共同工作,使模型能够识别和复制对高质量音乐作品至关重要的大规模结构。
![]()
官方提示词指导
Get more from your audio creations by adding structure to your prompts.
在提示语中加入结构,让音频创作发挥更大作用。There are a few ways you can structure your prompts using Format, Genre, Sub-genre, Instruments, Moods, BPM and Styles.
您可以使用格式、流派、子流派、乐器、情绪、节拍和风格等几种方法来构建提示。First, you need to think about what you want to create. For example, to create a single drum stem, start your prompt with ‘Format: Solo‘ and ‘Instruments: drum’.
首先,你要想好要创建什么。例如,要创建一个单独的鼓干,请在提示符下输入 “格式:独奏 “和 “乐器:鼓”:独奏 “和 “乐器:鼓”。It’s best to separate the prompt structure with a ‘|’.
最好用”|”分隔提示结构。
Example: Format: Solo | Instruments: drum.
举例说明:格式:独奏 | 乐器:鼓。
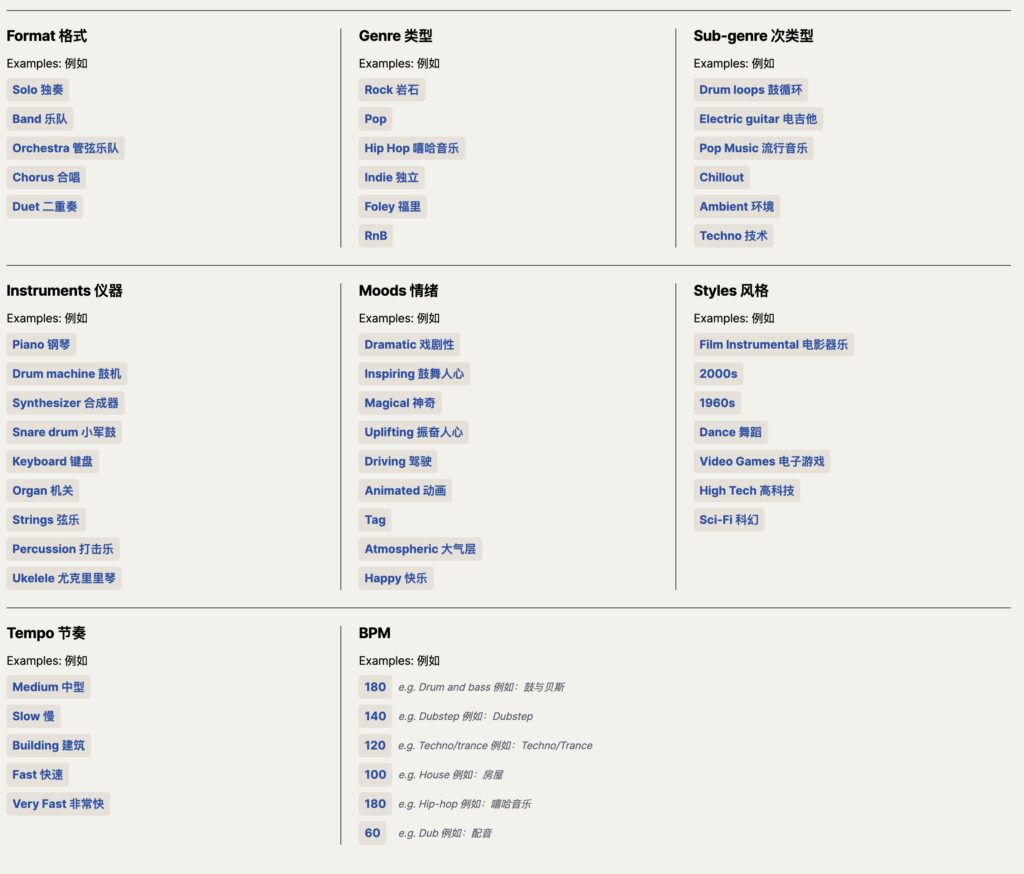
提示词指南:https://stableaudio.com/user-guide/prompt-structure
官方介绍:https://stability.ai/news/stable-audio-2-0
在线体验:stableaudio.com













{kind=link}