

Google 宣布 Gemini 1.5 Pro 开放API 现已在180多个国家提供 新增对原生音频(语音)理解能力、文件API、系统指令、JSON模式等功能 现在Gemini模型能够直接处理音频输入,而不需要将音频先转换为文本。
新的模态
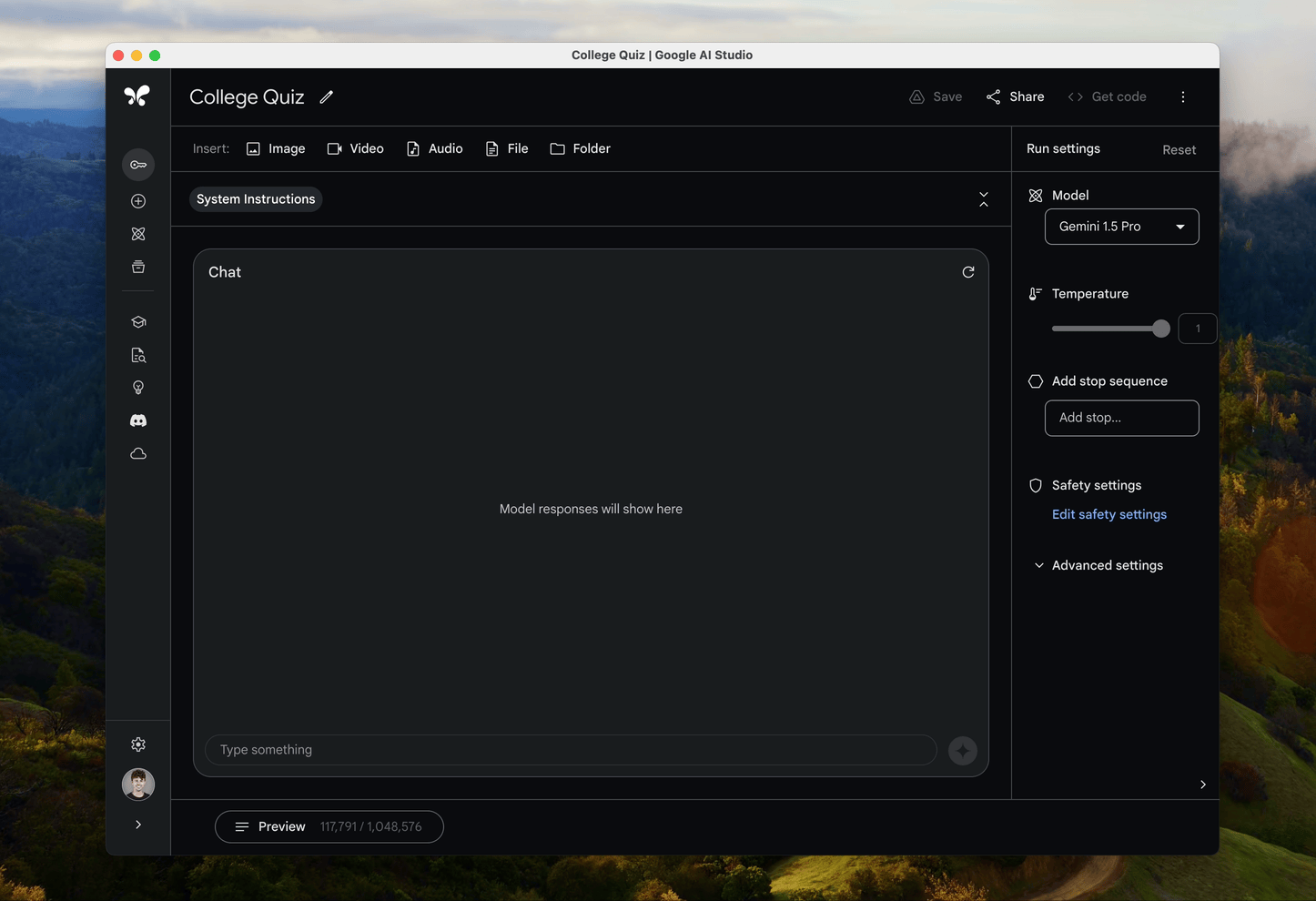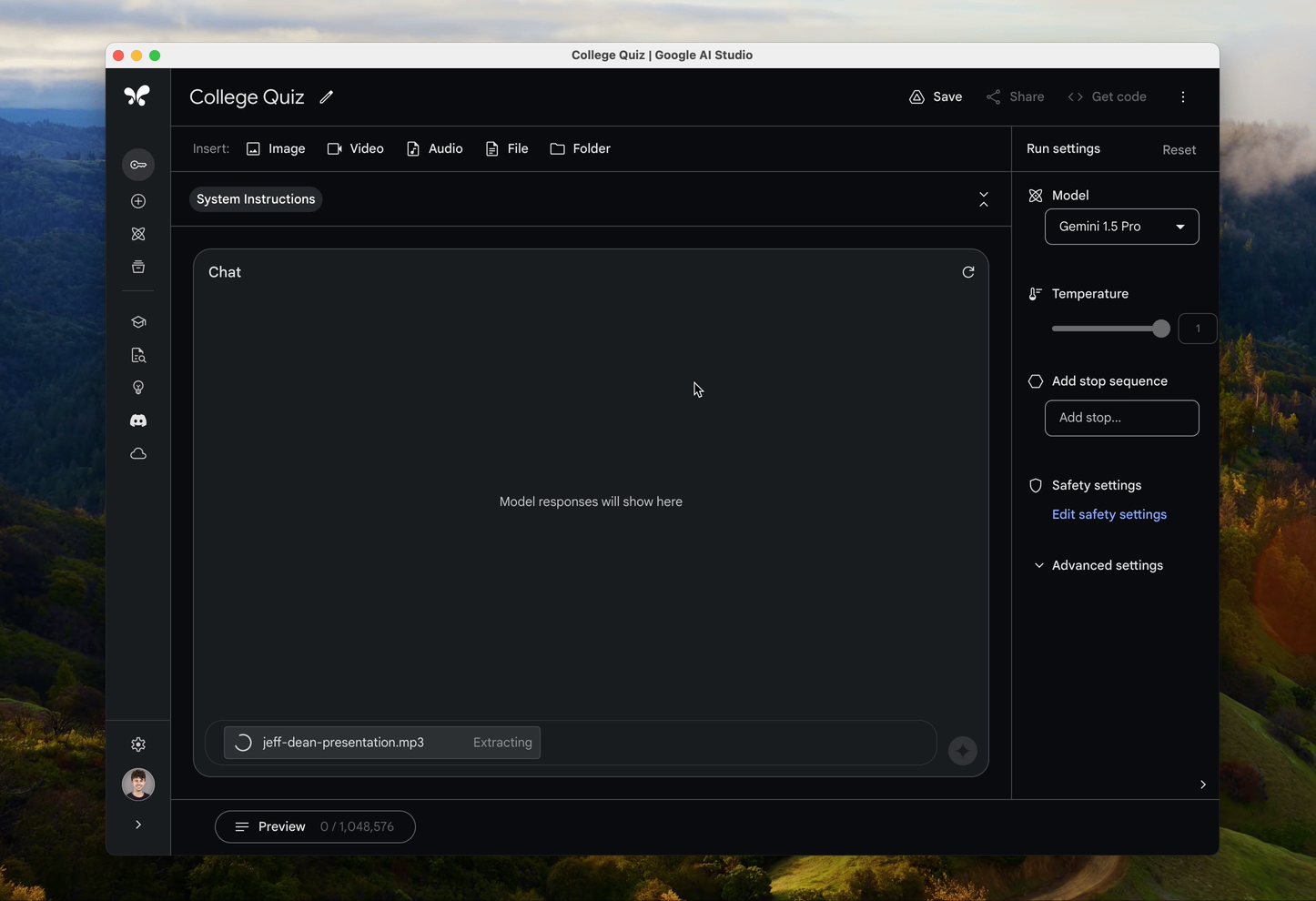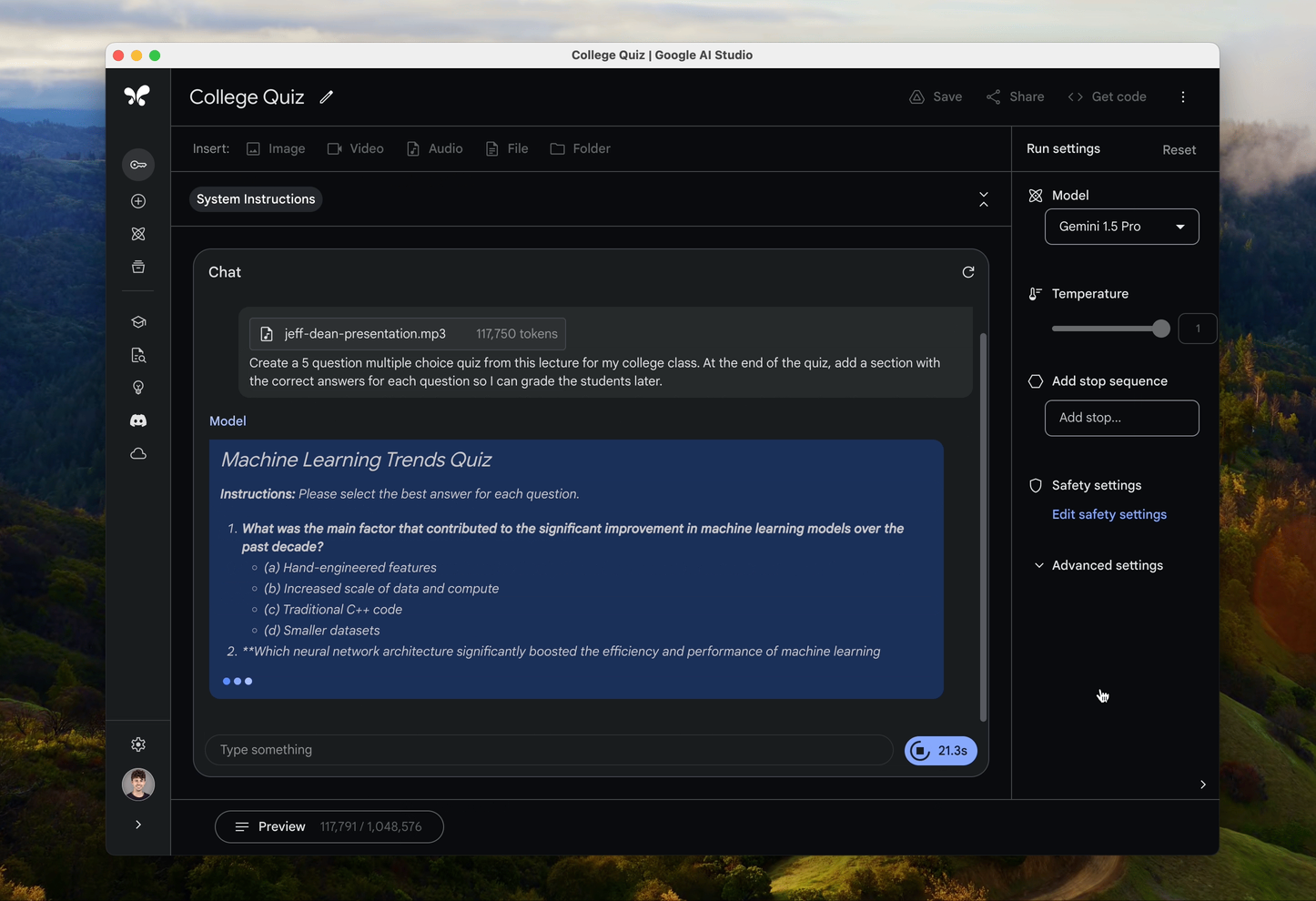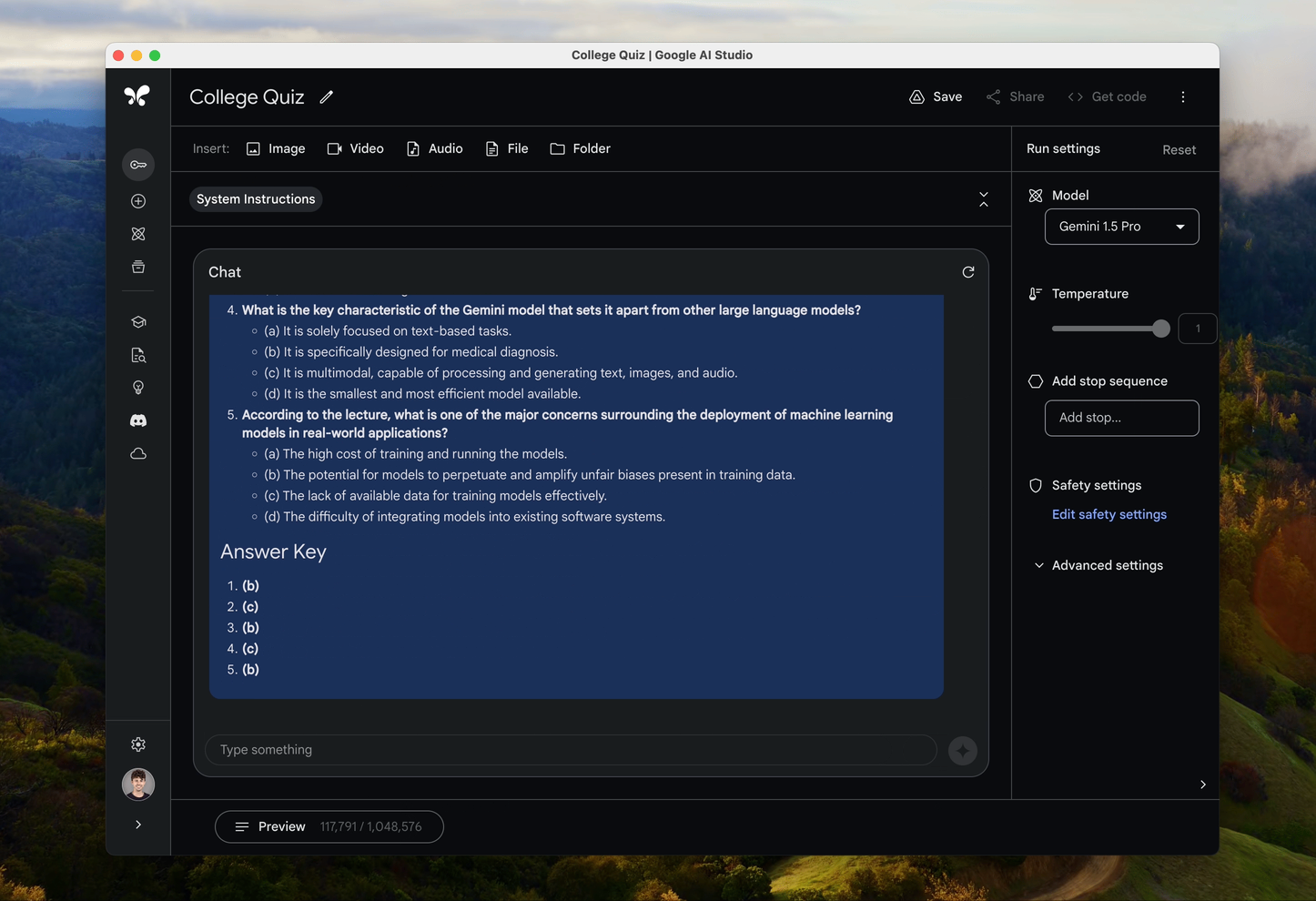
- 原声音频模态:Gemini 1.5 Pro 扩展了输入模态,包括在 Gemini API 和 Google AI Studio 中理解原生音频(语音)。原生音频理解能力指的是模型能够直接处理音频输入,而不需要将音频先转换为文本。这包括直接从音频数据中提取信息、理解语音命令、执行语音到语音的转换等。这一能力大大扩展了AI的应用场景,使得开发者能够在音频和视频处理、交互式媒体、智能助理等领域构建更加丰富和高效的应用。
- 视频内容理解:Gemini 1.5 Pro能够对上传到Google AI Studio中的视频进行图像(帧)和音频(语音)的同时推理,意味着这个模型具备了理解和处理视频内容的能力,不仅限于视频的视觉部分(如图像帧),也包括音频部分(如对话、背景音乐等)。
应用潜力
-
多模态理解:Gemini 1.5 Pro能够综合视频中的视觉信息和音频信息,进行更全面的内容理解。例如,它可以通过分析视频帧中的场景和物体,同时听取视频中的对话或声音,来更准确地识别和解释视频内容。
-
内容索引和搜索:通过对视频图像和音频的深入理解,Gemini 1.5 Pro可以帮助创建更详细的内容索引,使用户能够基于视频内容的视觉和听觉信息进行搜索。
-
增强的交互体验:利用对视频的综合理解,可以开发更丰富的交互式应用,比如自动生成视频摘要、基于内容的推荐系统,或者创建互动式学习和娱乐体验。
-
视频内容分析:Gemini 1.5 Pro可以用于视频监控、内容审查、情感分析等场景,通过同时理解视频和音频内容,AI可以自动识别视频中的关键事件、情感倾向或者特定的内容标签。
-
创意内容生成:对视频图像和音频的综合理解也使得Gemini 1.5 Pro能够在内容创作领域发挥作用,如自动生成视频字幕、配音或者根据给定的脚本制作动画视频。
Gemini API 改进
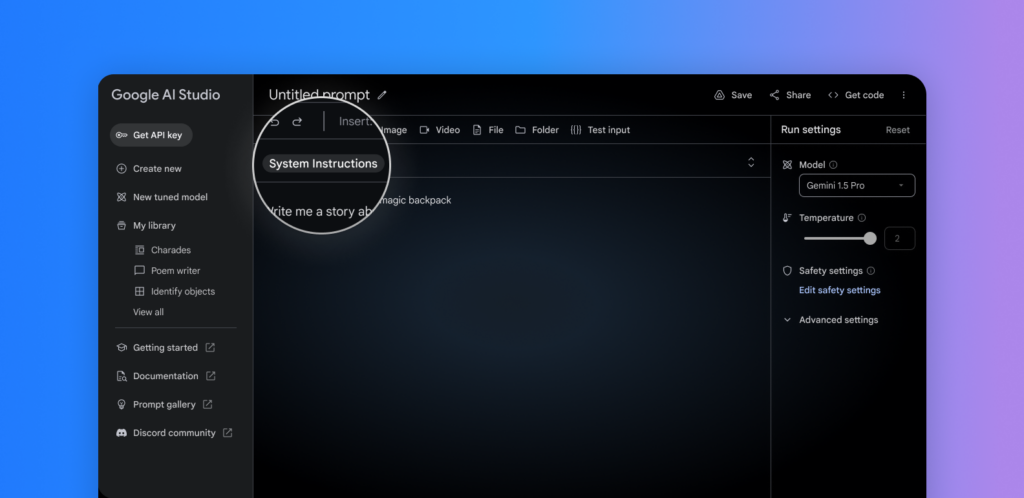
- 系统指令:通过系统指令,开发者可以引导模型的响应,为特定的用例定义角色、格式、目标和规则,从而更精准地控制模型行为。
- JSON 模式:指示模型仅输出JSON对象。该模式支持从文本或图像中提取结构化数据。可以使用cURL开始,并且Python SDK支持即将推出。
- 函数调用的改进:改进了函数调用功能,开发者现在可以选择模式来限制模型的输出,提高输出的可靠性。
新的嵌入模型
推出了性能更优的下一代文本嵌入模型 text-embedding-004(在 Vertex AI 中为 text-embedding-preview-0409),在 MTEB 基准测试中展现出更强的检索性能,超过了所有现有的具有可比维度的模型。
文件API
使用文件API上传文件
- 文件API支持上传包括图像和音频格式在内的多种多模态MIME类型的文件。接受大小在2GB以下的文件,并且可以存储每个项目高达20GB的文件。文件在API中的存储期限为2天,不能从API下载。
- 指导文档提供了如何准备示例图像并上传到API的步骤。上传后,可以使用
files.get来验证API是否成功接收文件,然后在GenerateContent请求中引用文件API URI。
支持的文件格式
- Gemini模型支持使用多种文件格式进行提示。对于图像、音频和视频文件的使用考虑了特定的限制和要求。
- 图像格式:支持PNG、JPEG、WEBP、HEIC、HEIF等图像数据MIME类型。对于gemini-pro-vision模型最多支持16张个别图像,对于gemini-1.5-pro模型最多支持3600张图像。
- 音频格式:支持WAV、MP3、AIFF、AAC、OGG Vorbis、FLAC等音频格式MIME类型。单个提示中音频数据的最大支持长度为9.5小时。
- 视频格式:虽然Gemini API不直接支持视频文件格式作为输入,但可以通过将视频分解成一系列静止帧图像和一个单独的音频文件来使用视频数据作为提示输入。
详细信息请访问:Google 官方网站
音频理解能力详见:GitHub – google-gemini/cookbook















{kind=link}