
Adobe 推出了新的 Firefly Image 3 Model模型,这是继 Adobe Firefly 发布一年后的又一重大进展。这个新模型现已在 Firefly 网页应用、Adobe Photoshop 和 Adobe InDesign 中以 beta 版本提供,它带来了更高级别的创意表达和控制能力。Adobe Firefly Image 3 Model 引入了多项新功能和显著的能力提升,进一步增强了创意专业人士和设计师在图像生成领域的工作效率和创造力。
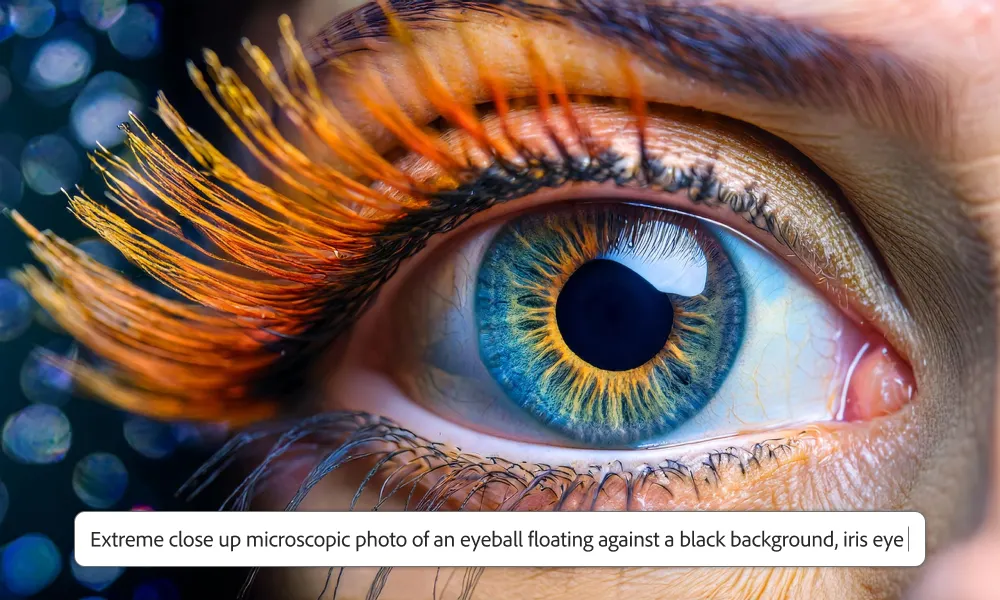
新的 Image 3 Model 拥有改进的图形处理能力、更精准的文本提示解释,甚至能够指导图像的构图。
-
改进的图形处理能力:能够生成更高质量、更逼真的图像,图形细节和视觉效果得到显著提升。
-
更精准的文本提示解释:新模型对用户输入的文本提示有更好的理解能力,能更准确地根据这些提示生成符合用户期望的图像内容。
-
指导图像构图的能力:模型不仅能生成图像,还能在一定程度上指导或控制图像的布局和构图,例如通过引入结构参考和风格参考功能,帮助用户更好地实现其创意意图。
主要功能
-
高质量图像生成:
- 新模型能产生更高质量的图像,这些图像在视觉效果上更为逼真,细节和风格处理上更加精准。
-
优化的提示解释:
- Firefly Image 3 Model 对输入的文本提示有更好的解释能力,能更准确地理解和转化为相关的图像内容。
-
自动风格应用:
- 根据用户的提示自动应用匹配的风格,使创作过程更为直观和便捷。
-
文本在图像中的准确呈现:
- 模型在图像中嵌入文本的能力得到增强,能更准确地展示和布局文本元素。
- 模型在图像中嵌入文本的能力得到增强,能更准确地展示和布局文本元素。
能力提升
-
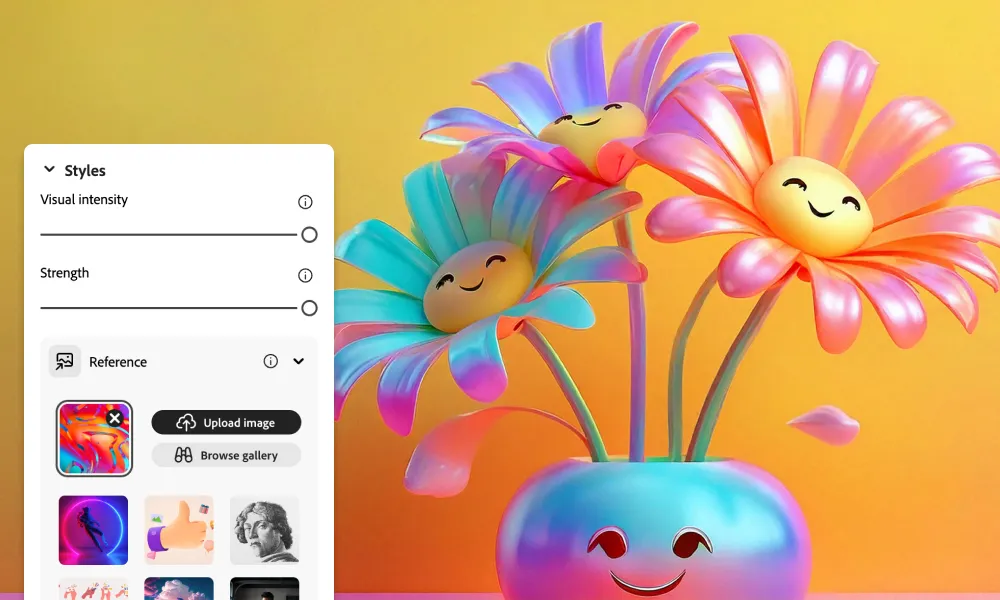
结构参考和风格参考:
- 结合了最近发布的结构参考和风格参考功能,提供了前所未有的用户控制能力,允许用户指导模型更精确地生成符合特定视觉结构和风格的图像。
-
参考图像的改进处理:
- 模型现在能更有效地结合参考图像和文本提示,减少了用户在生成期望图像时的试错需求。
-
对复杂提示的深入理解:
- 对长而复杂的文本提示有更深入的理解,能生成更丰富详细的图像,这些图像更好地反映了用户的创意愿景。
-
生成填充和扩展功能:
- 通过在 Firefly 网页应用的生成填充模块中引入“生成扩展”功能,用户可以更灵活地调整原始图像的纵横比或尺寸,以满足内容需求,如增加文本空间或适应特定的图像规格。
在线体验:https://firefly.adobe.com/inspire/images
生成式填充测试地址:https://firefly.adobe.com/upload/inpaint
- 通过在 Firefly 网页应用的生成填充模块中引入“生成扩展”功能,用户可以更灵活地调整原始图像的纵横比或尺寸,以满足内容需求,如增加文本空间或适应特定的图像规格。












{kind=link}