
Nvidia的CEO黄仁勋在Computex 2024大会上透露,未来的DLSS(深度学习超级采样)技术将利用AI来生成游戏中的纹理、角色和物体。这意味着游戏的画面和角色可以由AI自动生成,从而提高游戏的性能。
- 提升游戏性能:
- 通过将工作转移到专门的AI处理单元,减少对主要处理单元的压力,提高游戏帧率。
- 自动生成游戏内容:
- DLSS可以自动生成高质量的游戏纹理和物体,提升游戏画面质量。
- AI生成的NPC(非玩家角色)可以让游戏中的对话和互动更加生动有趣。
- 新技术:
- Nvidia正在开发新的纹理压缩技术,可以在不增加显存需求的情况下大幅提升纹理质量。
 在 Computex 2024 的问答环节中(由 More Than Moore 报道),黄仁勋回答了一个与 DLSS 相关的话题,称未来我们将看到完全通过 AI 生成的纹理和物体。黄仁勋还表示,AI NPC 也将完全通过 DLSS 生成。
在 Computex 2024 的问答环节中(由 More Than Moore 报道),黄仁勋回答了一个与 DLSS 相关的话题,称未来我们将看到完全通过 AI 生成的纹理和物体。黄仁勋还表示,AI NPC 也将完全通过 DLSS 生成。
通过 DLSS 生成游戏内资产将有助于提升 RTX GPU 的游戏性能。将工作转移到张量核心上将减少对着色器 (CUDA) 核心的需求,从而释放资源并提高帧率。黄仁勋解释说,他认为 DLSS 能够自行生成纹理和物体,并改善物体质量,就像今天 DLSS 对帧进行超分一样。
Nvidia的DLSS(深度学习超级采样)技术是Turing架构中最具前景的功能之一。DLSS通过利用深度神经网络,从渲染场景中提取多维特征,并智能地结合多个帧的细节来构建高质量的最终图像,从而提高性能和画面质量。

- DLSS与TAA的对比:
- 性能提升:DLSS在QHD和4K分辨率下提供了比传统抗锯齿(TAA)更好的性能,尤其是在高分辨率下,DLSS的效果更加明显。
- 画质分析:在一些场景中,DLSS的图像质量超过了TAA,特别是在背景植被等细节处表现更佳。然而,在某些场景中,DLSS的边缘处理仍然会出现锯齿。
- DLSS的工作原理:
- 多帧细节融合:DLSS通过深度神经网络从多个渲染帧中提取细节信息,智能地填补缺失像素。这种方法不仅提高了图像质量,还减少了对GPU核心的压力。
- AI图像处理:利用AI技术进行图像处理,使得Turing GPU可以使用更少的样本进行渲染,通过Tensor核心补充细节,最终生成高质量图像。
- 实际效果:
- 4K分辨率的优势:在4K分辨率下,DLSS的效果明显优于QHD,提供了更清晰和细腻的画面输出。在某些游戏中,如《最终幻想XV》,DLSS的表现接近完美。
- 局限性:在某些新场景的第一个帧中,DLSS会暴露其真实分辨率,使画面质量略有下降。此外,在某些中间帧中,锯齿现象仍然存在。
- 技术挑战与未来发展:
- 细节处理:虽然DLSS在大多数情况下表现出色,但在某些复杂场景中,边缘处理和细节保留仍有改进空间。
- 新技术的引入:Nvidia正致力于开发新的技术,如AI驱动的纹理压缩,以进一步提升图像质量和渲染效率。

 Nvidia 已经在开发一种新的纹理压缩技术,该技术考虑了经过训练的 AI 神经网络,在保留当今游戏视频内存 (VRAM) 需求的同时显著提升纹理质量。传统的纹理压缩方法的压缩比限制为 8 倍,而 Nvidia 的新神经网络压缩技术可以将纹理压缩比提高到 16 倍。
Nvidia 已经在开发一种新的纹理压缩技术,该技术考虑了经过训练的 AI 神经网络,在保留当今游戏视频内存 (VRAM) 需求的同时显著提升纹理质量。传统的纹理压缩方法的压缩比限制为 8 倍,而 Nvidia 的新神经网络压缩技术可以将纹理压缩比提高到 16 倍。
这种方法可以在保持相同存储需求的情况下,提供比传统方法高四倍的分辨率。新的技术利用神经网络来压缩和解压缩游戏中的纹理,使得画面质量更高。
主要亮点:
- 更高的画质:
- 新方法提供了比传统块编码方法高16倍的纹理像素,从而实现4倍的分辨率(支持最高8192×8192的分辨率),并保持类似的存储需求。
- 可以实现最高8192×8192的超高分辨率。
- 神经网络解压缩:
- 使用专门训练的神经网络来解压缩纹理。
- 这些神经网络运行在Nvidia GPU的张量核心上,不需要特殊硬件。
- 实际效果:
- NTC比传统方法更耗时,但能提供更高的纹理质量。在4K图像渲染中,NTC纹理需1.15毫秒,而传统BC纹理需0.49毫秒。
- 在复杂的游戏场景中,这项技术能通过同时执行其他任务(如光线追踪)来部分抵消其计算开销。
黄仁勋对未来 DLSS 迭代的更有趣的方面是游戏内资产生成。Nvidia 的 DLSS 3 帧生成技术通过在真实帧之间生成帧来提升性能。资产生成是超越 DLSS 3 帧生成的一步,通过 DLSS 完全从零开始生成游戏内资产。(DLSS 需要知道在游戏世界中需要放置资产的位置以及需要渲染哪些资产,但它们将完全从零开始生成。)
**DLSS 3(深度学习超级采样)**是Nvidia的一项创新技术,通过利用AI技术来提升游戏的图像质量和性能。
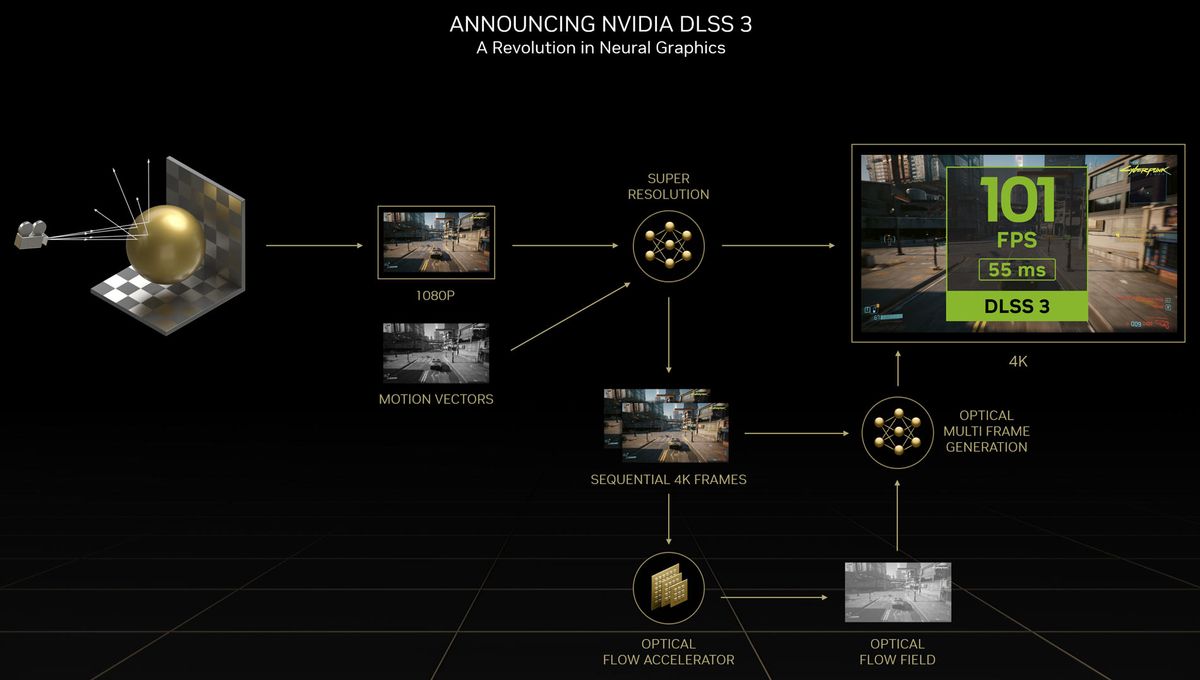
1. AI驱动的帧生成
- 新帧生成技术:DLSS 3引入了帧生成技术,利用AI在现有帧之间生成新的帧,从而提高帧率。这个过程减少了GPU的计算负担,使游戏运行更加流畅。
- 性能提升:通过在现有帧之间插入AI生成的帧,DLSS 3可以显著提高游戏的帧率,特别是在高分辨率下。
2. 高质量图像
- 细节增强:DLSS 3能够智能地结合多个帧的细节,构建出高质量的最终图像。相比传统的抗锯齿技术(如TAA),DLSS 3在保持图像清晰度和细节方面表现更佳。
- 纹理质量:DLSS 3利用AI技术提高纹理质量,减少图像中的模糊和锯齿现象,使游戏画面更加逼真。
3. 广泛的游戏支持
- 兼容性:DLSS 3已经在多个热门游戏中得到支持,如《极品飞车:不羁》、《战锤40K:暗潮》、《传送门RTX版》、《侏罗纪世界进化2》和《巫师3:狂猎》。此外,还有更多游戏即将支持这一技术。
- 向下兼容:尽管DLSS 3主要针对最新的Ada Lovelace架构显卡,但DLSS 3游戏在上一代GeForce RTX显卡上也能兼容DLSS 2。
4. 延迟优化
- Nvidia Reflex:DLSS 3结合了Nvidia Reflex技术,通过优化输入延迟,确保游戏操作的响应速度。这一结合能够在提升帧率的同时,尽量减少延迟的增加。
5. 易于使用
- 一键优化设置:通过GeForce Experience,用户可以轻松地为支持DLSS 3的游戏应用一键优化设置,简化了图像质量和性能的调整过程。
黄仁勋还讨论了 DLSS 在 NPC 方面的未来。不仅黄仁勋预计 DLSS 能生成游戏内资产,他还设想 DLSS 能生成 NPC。他举了一个例子,在一个视频游戏中存在六个人,其中两个人是真实角色,而另外四个人则完全由 AI 生成。














{kind=link}