

IMAGDressing-v1 是一个自定义虚拟试衣系统,可生成可自由编辑的人像图像。该系统主要面向商家,帮助他们全面展示服装,并灵活控制面孔、姿势和场景。IMAGDressing-v1 结合了多种技术,包括服装UNet和混合注意力模块,以实现高质量的人像合成。
解决了什么问题?
- 增强消费者在线购物体验:通过生成逼真的虚拟试穿效果图,IMAGDressing-v1 提升了消费者在电子商务平台上的购物体验。
- 提供商家更灵活的服装展示方式:现有的虚拟试穿技术主要集中在固定人像条件下展示服装,缺乏灵活性和可编辑性。IMAGDressing-v1 解决了这一问题,使商家能够灵活地控制面孔、姿势和场景,从而全面展示服装。
- 解决数据不足问题:IMAGDressing-v1 发布了互动服装配对(IGPair)数据集,包含超过30万对服装和穿着图像,提供了一个标准的数据组装管道,支持进一步的研究和探索。
- 提高生成图像的多样性和可控性:通过与其他扩展插件(如ControlNet和IP-Adapter)结合,IMAGDressing-v1 增强了生成图像的多样性和可控性,使其在各种条件下都能生成高质量的图像。
- 优化技术实现:IMAGDressing-v1 采用了混合注意力模块和预训练的UNet模型,显著提高了生成图像的细节保留和一致性,解决了传统GAN方法在处理复杂背景和纹理细节方面的不稳定性问题。
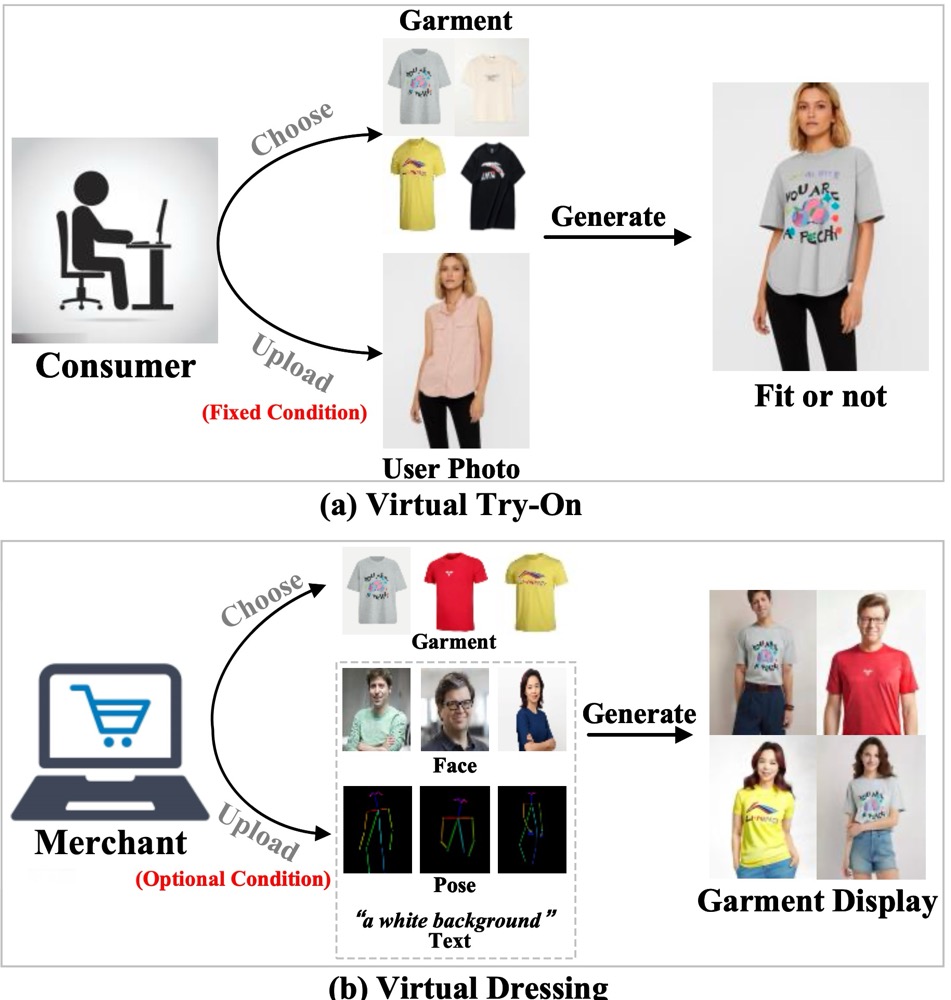 功能特点
功能特点
- 可编辑人像图像生成:
- IMAGDressing-v1 能够生成带有固定服装的可自由编辑的人像图像,用户可以灵活调整面孔、姿势和场景。
- 高质量服装展示:
- 系统能够捕捉和展示服装的细节和质感,确保生成的图像看起来非常真实和清晰。

- 系统能够捕捉和展示服装的细节和质感,确保生成的图像看起来非常真实和清晰。















{kind=link}