
AudioNotes 是一个基于 FunASR 和 Qwen2 构建的音视频内容转结构化笔记系统。它的主要功能是快速提取音视频的内容,并通过调用大模型进行整理,将这些内容转换为结构化的Markdown笔记,便于用户快速阅读和理解。
- 音视频内容识别:利用先进的自动语音识别(ASR)技术,能够精准地提取音视频中的文本内容。
- 结构化笔记生成:通过大模型对提取的内容进行整理,生成清晰、易读的Markdown笔记。
- 与音视频内容对话:支持用户与音视频内容进行交互式对话,以获取更多信息或进行深入探讨。
AudioNotes 主要功能包括:
- 音视频内容识别与提取:
- 利用 FunASR 自动语音识别技术,准确提取音频和视频中的文本内容。
- 支持多种音视频格式的处理,确保广泛的适用性。
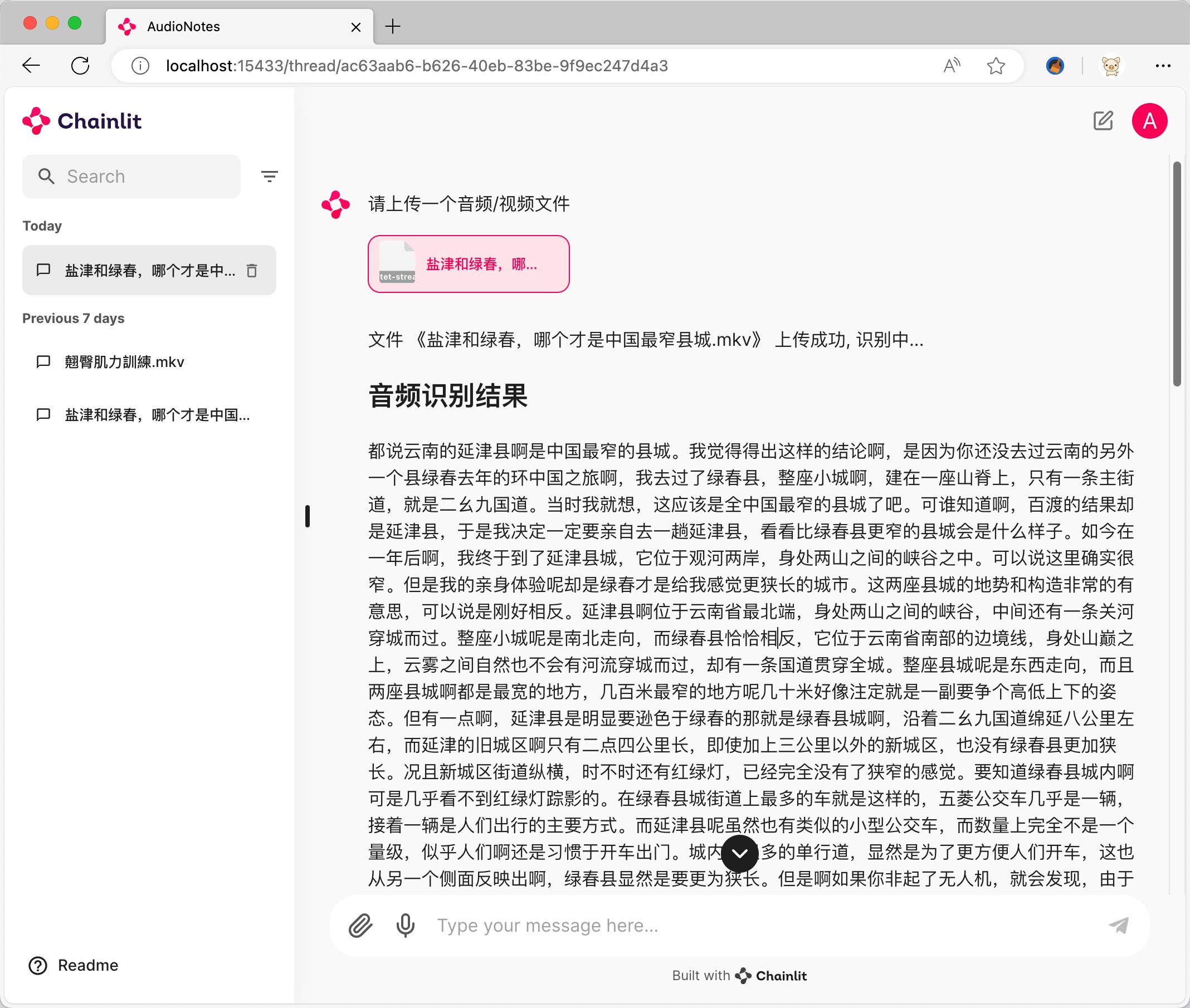
- 结构化笔记生成:
- 通过 Qwen2 大模型对提取的文本内容进行整理。
- 自动生成结构化的Markdown笔记,便于用户快速阅读和理解。
- 笔记内容条理清晰,包含关键信息和要点,减少用户手动整理的时间。
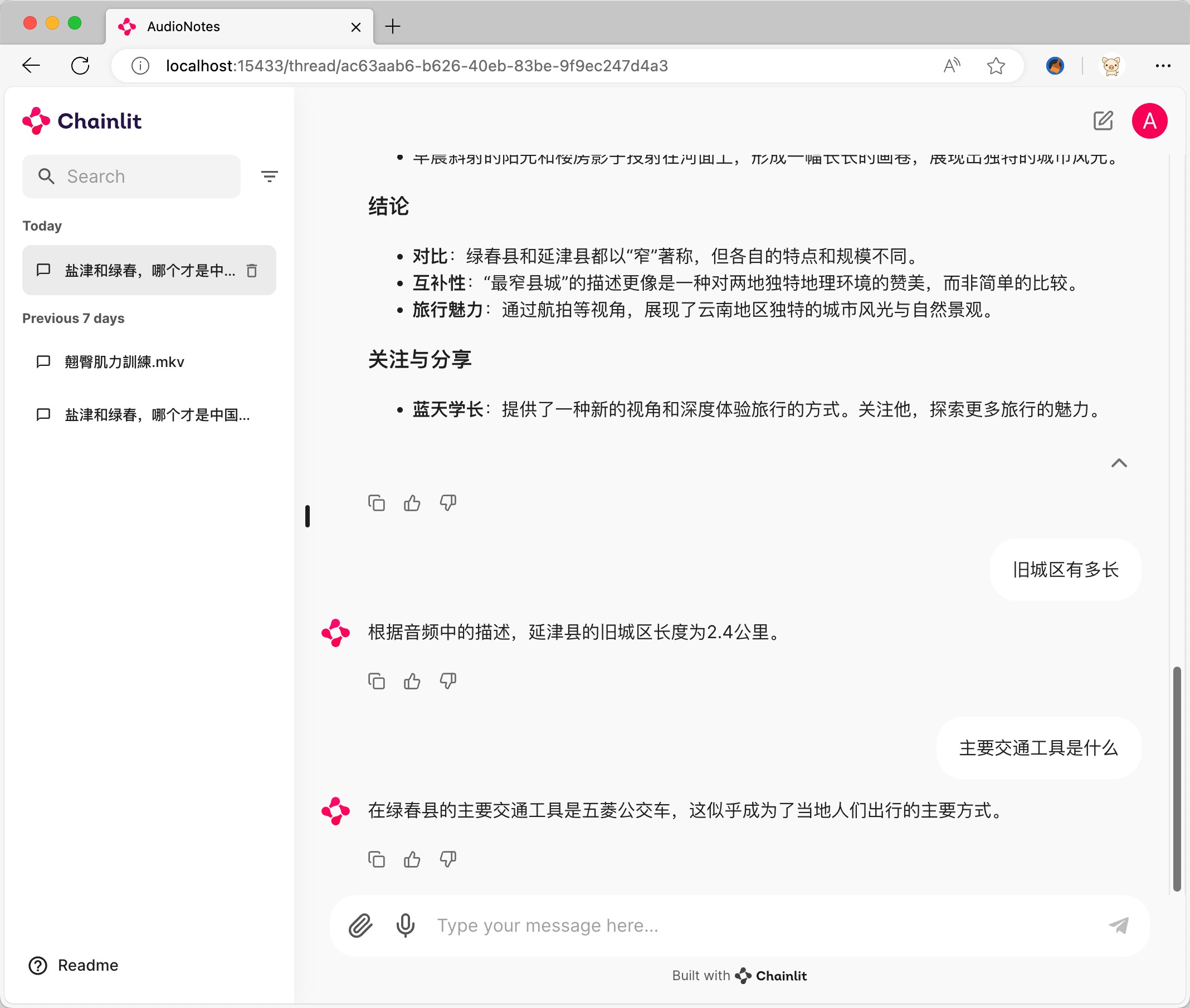
- 与音视频内容对话:
- 提供与音视频内容进行交互式对话的功能。
- 用户可以就音视频内容提问,系统会基于识别和整理的文本内容进行回答,提供深度信息获取的能力。














{kind=link}