
OutfitAnyone是由阿里巴巴开发的一个基于扩散模型的2D虚拟试穿框架,旨在解决现有虚拟试穿技术在生成高保真、细节一致的结果时遇到的挑战。
OutfitAnyone采用双流条件扩散模型,可以处理衣物变形,生成更加逼真的试穿效果。它具有可扩展性,能够适应不同的姿势、体型,并适用于从动漫到野外图像的广泛应用场景。
传统的虚拟试穿方法在处理不同体型和姿势时,衣物容易变形。OutfitAnyone通过双流条件扩散模型,有效解决了这个问题。具体来说:
- 保持衣物细节:能保持衣物的纹理、图案和形状,即使在不同体型和姿势下也能生成逼真的试穿效果。
- 适应不同体型和姿势:无论用户的体型或姿势如何变化,系统都能准确地调整衣物,确保其与用户的身体完美契合。
- 可扩展性:
- 系统支持多种姿势和体型,不论是静态姿势还是动态姿势,都能生成高质量的试穿效果。
- 通过姿势和体型指导(如openpose、SMPL等),系统能够准确地适应不同用户的体型和姿势变化。
- 广泛应用场景:
- 系统不仅适用于普通用户上传的自拍照片,也适用于专业模特的照片。
- 甚至可以应用于动漫角色的虚拟试穿,展示了其在不同图像类型中的适应性。
- 无论是在室内还是室外场景中,系统都能生成逼真的试穿效果,适应不同的背景和光照条件。

OutfitAnyone 主要功能特点
- 高保真度虚拟试穿:
- 利用双流条件扩散模型,OutfitAnyone 在生成虚拟试穿图像时能保持高保真度和细节一致性,使试穿效果更加真实。
- 广泛的适用人群:
- 该系统适用于不同年龄、性别和肤色的人群,甚至可以生成动漫人物的虚拟试穿效果。无论是专业模特照片还是普通用户的自拍照,OutfitAnyone 都能生成高质量的试穿结果。
- 多样化的衣物支持:
- 支持单件衣物和多件衣物的试穿,包括上装和下装的组合。OutfitAnyone 可以处理各种衣物风格,如长袖、短袖、裤子、裙子等。
- 灵活的体型和姿势适应:
- OutfitAnyone 通过姿势和体型指导,能适应不同的体型和姿势变化,保持试穿后的体型一致,生成逼真的穿衣效果。
- 背景和光照保留:
- 该系统能够在复杂的背景和光照条件下生成合理的试穿效果,确保生成图像与原始图像在光照和背景上的一致性。
- 细节修饰器:
- OutfitAnyone 配备了一个细节修饰器,可以进一步增强试穿图像的清晰度和纹理细节,使最终输出的图像更加生动和逼真。
- 高质量图像生成:
- 支持从384 x 684到1080 x 1920的灵活图像尺寸生成,确保试穿图像在不同分辨率下的高质量表现。
- 适应多种场景:
- OutfitAnyone 不仅适用于室内环境,也能在复杂的户外场景中生成逼真的服装光效,展示出极高的环境适应性。
- 时装设计辅助:
- 该系统可以帮助时装设计师生成独特和流行的服装设计,提供创意灵感,并能为单件上装生成潜在的下装设计建议,辅助设计过程。
技术方法
OutfitAnyone利用了一系列先进的技术方法来实现高质量的虚拟试穿效果。以下是其主要技术方法的详细解释:
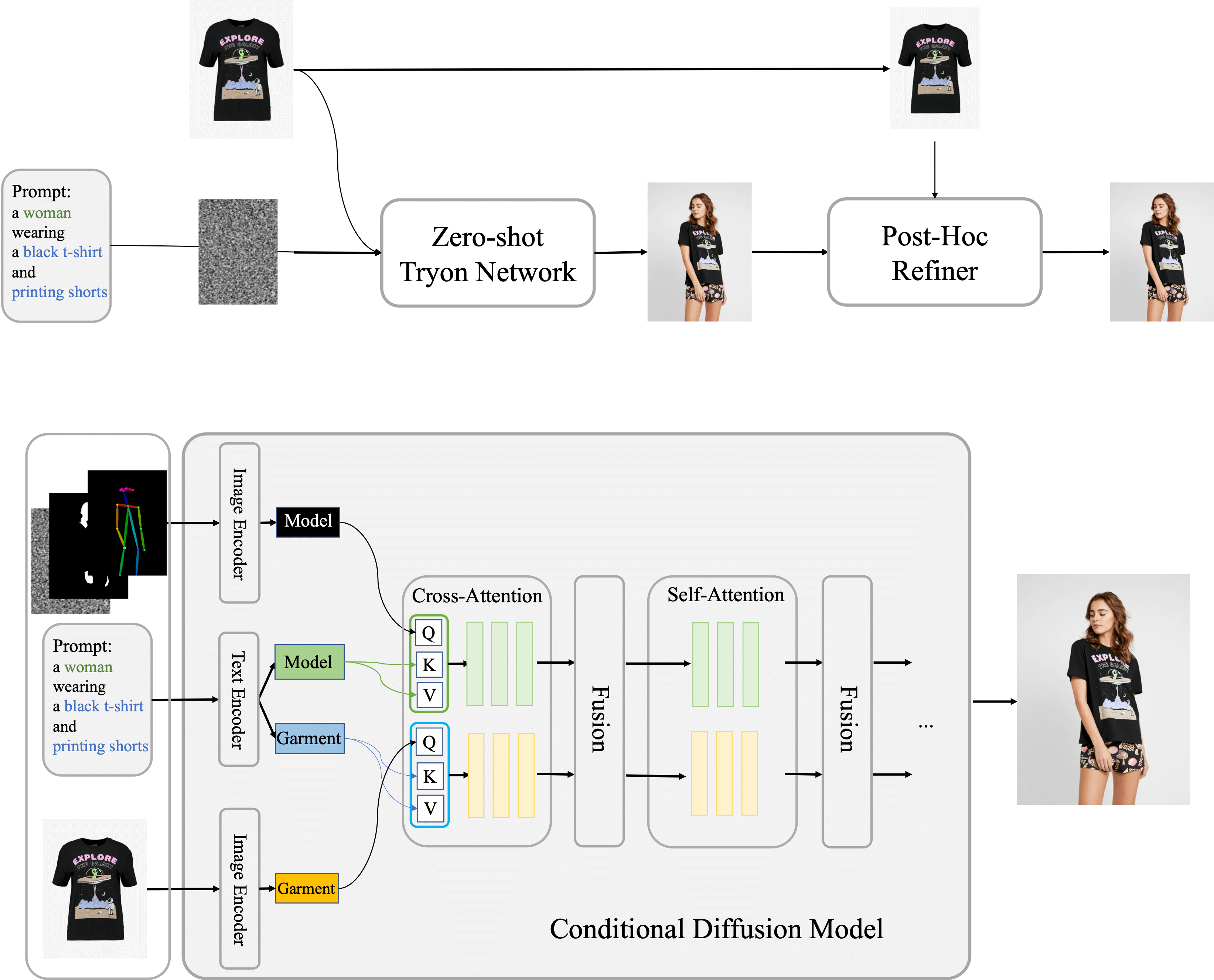
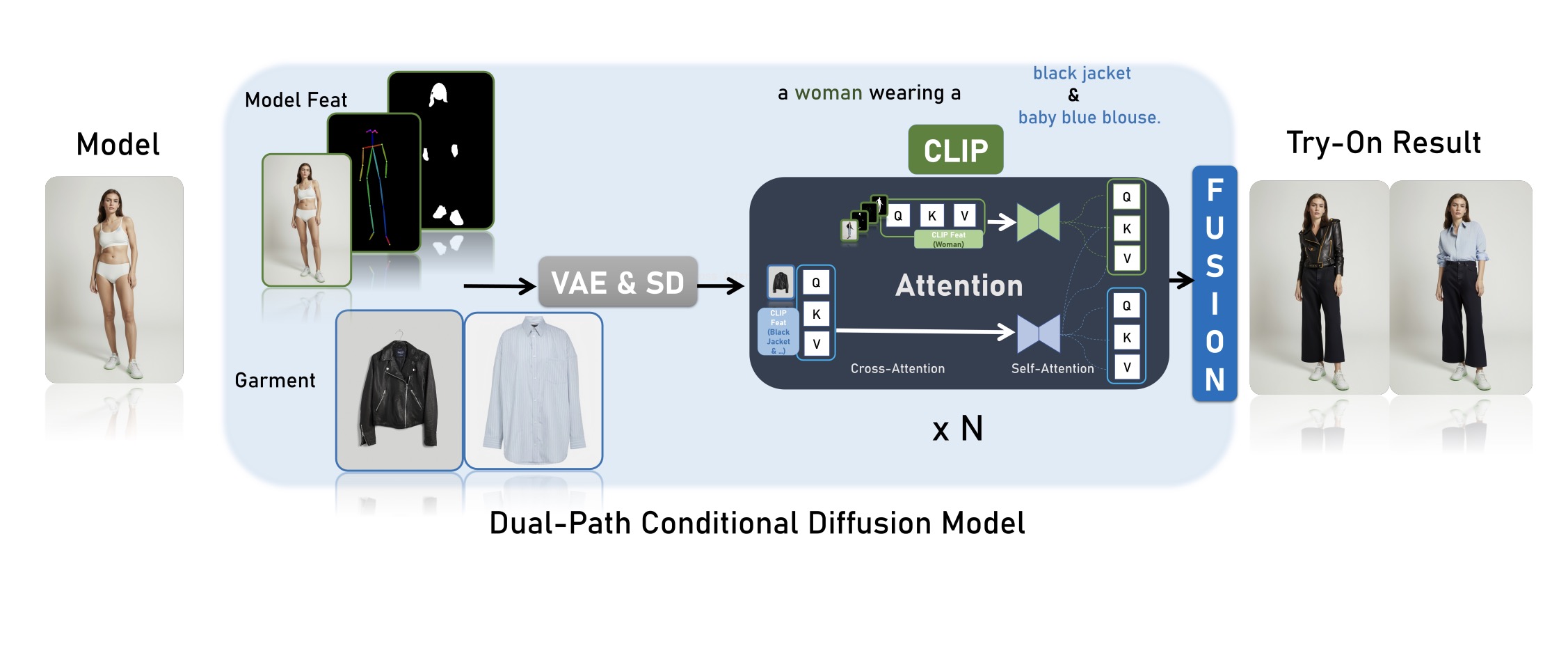
- 双流条件扩散模型
- 独立处理:系统分为两个独立的路径,每个路径分别处理人体数据和衣物数据。
- 人体流:处理用户上传的照片,包括姿势、体型等信息。
- 衣物流:处理用户选择的衣物图像,提取其纹理、图案等特征。
- 融合网络:这两个路径在融合网络中合并,将衣物细节和人体特征融合生成最终的试穿图像。
- 独立处理:系统分为两个独立的路径,每个路径分别处理人体数据和衣物数据。
- 衣物特征注入
- 稳定扩散(Stable Diffusion):使用预训练的自动编码器来提取衣物图像的特征,并将这些特征注入去噪管道。
- ReferenceNet:专门设计的衣物特征处理网络,镜像U-Net架构,通过空间注意力和交叉注意力层将衣物特征成功注入生成管道,提升生成图像的质量。
- 无分类器指导
- 分类器自由指导:利用无条件分类器指导技术,通过调整指导比例,生成更精确、一致的结果。具体来说,在虚拟试穿中,衣物图像作为主要控制元素,用无条件的空白衣物图像和有条件的实际衣物图像进行指导,确保生成的图像准确反映衣物细节。
- 背景和光照保留
- 背景一致性:为了保持生成图像与原始图像在背景和光照上的一致性,OutfitAnyone采用了擦除除脸和手之外的所有部分的方法,避免了掩模形状和风格的耦合。
- 背景还原:在需要生成大面积背景的情况下,系统可以使用精确的人物分割模型提取生成的人物并将其粘贴回原始背景。
- 姿势和体型指导
- 姿势控制:系统可以利用骨骼图像、密集姿势图像或SMPL模型图像实现姿势控制,无需额外的训练阶段或参数。
- 体型一致性:通过提取密集姿势数据(如SMPL或openpose),指导最终生成的模型保持与原始图像一致的体型。
- 细节修饰器
- 高低质量图像对:通过构建高低质量图像对,训练扩散模型恢复细节。
- 自循环修饰器:进一步增强试穿图像的清晰度和纹理细节,使最终输出图像更加生动逼真。
各种试穿结果
- 现实场景: 展示了多样的服装更换,包括完整装扮和单件服装。


- 单件服装: 展示了模型处理各种独特服装风格的能力。

- 各种体型: 能够推广到各种体型,满足不同个体的试穿需求。


- 动漫: 支持创建新的动画角色。


- 细化器: 提高了服装的质感和真实感,同时保持服装的一致性。

-
奇异时尚:各














{kind=link}