Medical SAM 2 (MedSAM-2),一个基于SAM 2框架的高级分割模型,解决2D和3D医学图像分割任务。
通过将医学图像视为视频,MedSAM-2不仅适用于3D医学图像,还引入了一种新的单次提示分割功能(One-prompt Segmentation),即用户只需为某一图像提供提示,模型即可自动分割后续所有相似目标,无需再提示。

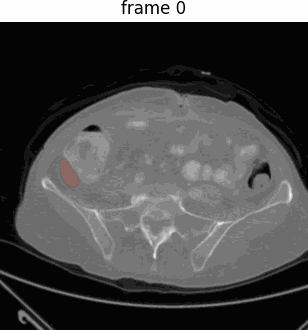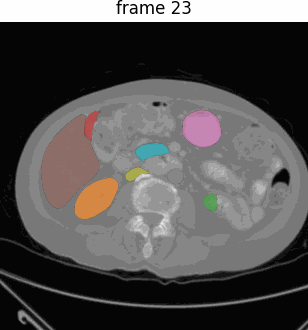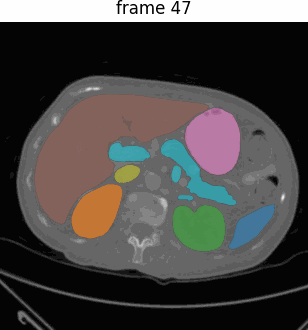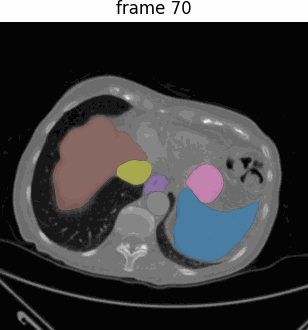
Medical SAM 2 (MedSAM-2),一个基于SAM 2框架的高级分割模型,解决2D和3D医学图像分割任务。
通过将医学图像视为视频,MedSAM-2不仅适用于3D医学图像,还引入了一种新的单次提示分割功能(One-prompt Segmentation),即用户只需为某一图像提供提示,模型即可自动分割后续所有相似目标,无需再提示。















{kind=link}