
主要特点和功能
-
音频驱动的人像视频生成: 利用单张参考图像和音频输入(如说话或唱歌),EMO能够生成具有表情变化和头部动态的虚拟人像视频。这意味着用户可以通过提供一张静态图片和相应的音频文件,来创造出说话或唱歌的动态视频。无论视频中的人物进行怎样的表情变化或头部动作,其基础特征都来源于这张参考图片。
-
表情丰富的动态渲染: EMO特别强调在视频中生成自然而富有表情的面部动作,能够捕捉到音频中情感的细微差别,并将其反映在人像的表情上,从而生成看起来自然、生动的面部动画。
-
多头部姿势支持: 除了面部表情外,EMO还能够根据音频生成多样的头部姿势变化,增加了视频的动态性和真实感。
-
支持多种语言和肖像风格: 该技术不限于特定语言或音乐风格,能够处理多种语言的音频输入,并且支持多样化的肖像风格,包括历史人物、绘画作品、3D模型和AI生成内容等。
-
快速节奏同步: EMO能够处理快节奏的音频,如快速的歌词或说话,确保虚拟人像的动作与音频节奏保持同步。
-
跨演员表现转换: EMO能够实现不同演员之间的表现转换,使得一位演员的虚拟形象能够模仿另一位演员或声音的特定表演,拓展了角色描绘的多样性和应用场景。
工作原理
EMO项目的工作原理基于以下几个关键步骤:
-
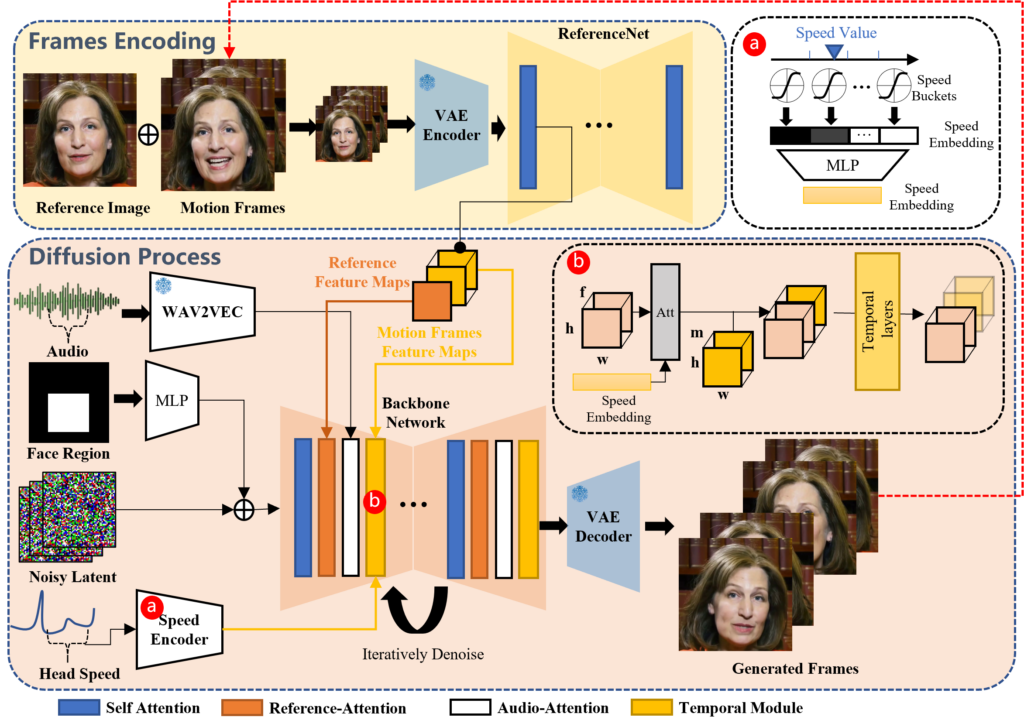
帧编码(Frames Encoding): 在这一阶段,使用名为ReferenceNet的网络从给定的参考图像和运动帧中提取特征。这包括识别人像的关键特征,如面部轮廓、眼睛、嘴巴等位置和形状。
-
音频处理: 通过预训练的音频编码器对输入的音频进行处理,得到音频嵌入。这个过程涉及到分析音频的节奏、音高和音量等信息,以便后续生成与音频同步的面部表情和头部动作。
-
扩散过程(Diffusion Process): 在这一阶段,结合音频嵌入和多帧噪声,通过一个称为背景网络的深度学习模型进行去噪操作,生成面部图像。背景网络内部利用了两种注意力机制:参考注意力(Reference-Attention)和音频注意力(Audio-Attention),分别用于保持人物身份的一致性和调节人物的动作。
-
时间模块(Temporal Modules): 为了处理视频中的时间维度,使用时间模块来调整运动的速度,确保视频中的动作平滑且自然。
-
生成视频: 最终,将处理后的帧序列合成为视频,每一帧都包含了与输入音频同步的表情和头部姿势变化。通过这种方式,EMO能够生成表情丰富、动作自然的人像视频,长度可以根据输入音频的时长自由调整。
具体步骤
具体来说,这个过程包含几个关键步骤:
-
参考图片: 用户提供一张人像图片作为参考,这张图片决定了视频中人物的基本外观。这意味着,无论视频中的人物进行怎样的表情变化或头部动作,其基础特征都来源于这张参考图片。
-
声音输入: 用户还需要提供一段声音输入,这可以是一段对话、朗读或歌唱。这段声音不仅仅是视频的音轨,更是驱动人物表情和头部姿势变化的关键。
-
表情和姿势生成: 基于声音输入,EMO技术分析其节奏、音调和强度等特征,然后根据这些音频特征,生成与之相匹配的面部表情和头部姿势。比如,当音频中出现高兴的声音时,视频中的人物就会展示出笑容;当音频节奏加快时,人物的头部动作也会相应变得更加活跃。
-
视频持续时间的调整: 生成的视频长度并不是固定的,而是可以根据输入音频的长度灵活调整。这意味着,无论提供的音频是一小段对白还是一整首歌曲,EMO都能生成与之长度相匹配的视频。
一些演示
项目地址:https://humanaigc.github.io/emote-portrait-alive/













{kind=link}