

SeedEdit 是一个AI图像编辑工具,由 Doubao 团队开发。它的特殊之处在于,可以根据用户输入的文字指令直接对图像进行编辑。
也就是你只需要通过简单的文字描述来修改图像,对图片进行各种复杂的修改,不需要专业的图片处理技能,不需要其他任何操作,不用再相Photoshop那样复杂的操作才能修改编辑图像。
无论是改变图像的内容、风格,还是调整光线和角度,SeedEdit 都可以实现,并保持高质量的编辑效果。
比如,用户可以输入“把图像中的房子换成城堡”,SeedEdit 就会自动识别并修改图像,替换成符合描述的效果。
SeedEdit 支持多种类型的图像编辑任务,包括:
- 局部替换:修改图像中的某一部分,例如将图片中的某个对象替换为另一个。
- 几何变换:如调整物体的大小、角度等。
- 光照调整:改变光照方向或效果。
- 风格更改:转换图像的艺术风格或色调。
- 组合编辑:支持同时进行多种编辑任务,以实现复杂的效果。
创新亮点
- 丰富的数据生成:生成大量多样化的编辑数据,解决了缺少训练数据的问题。
- 双分支架构:允许图像和文本指令之间有效“沟通”,保证了编辑的精度和一致性。
- 渐进式优化:逐步提高模型的稳定性和适应性,确保在复杂任务下也能表现优异。
SeedEdit 的核心功能
- 根据文字指令编辑图像:
- SeedEdit 的核心功能在于它可以理解文字描述,然后根据这些描述去编辑图像。比如,你可以输入“让这栋房子漂浮在天空中”,SeedEdit 会自动识别你的需求,将图片中的房子调整到天空的位置,创造出奇幻的效果。
- 这种“文字到图像编辑”的功能非常方便,因为用户不需要掌握复杂的图像处理软件和技术。
- 常见的文本指令可以包括:
- “把头发颜色变成金色”
- “添加一些云在天空中”
- “让人物微笑”
- SeedEdit 能够精准理解这些自然语言描述,进行相应修改,这在传统的图像编辑工具中往往需要手动操作才能实现。
- 稳定的图像重建和连续修改:
- SeedEdit 不仅能够在初次编辑时生成高质量的图片,还可以支持多轮修改。比如,用户可以在修改完“让房子漂浮在天空中”之后,继续添加指令“改变风格为童话风”,SeedEdit 会基于之前的修改结果再做进一步调整,保持图像的稳定和美感。
- 在每一轮优化后,SeedEdit 能够更好地理解更细微的编辑指令,例如仅调整局部颜色、改变光照方向、或添加微小物件等,而不会对其他区域产生多余的改动。
- 精确处理各种细节修改:
- SeedEdit 支持多种类型的编辑,涵盖从微小细节调整到大范围内容替换的各种需求,能够处理不同的修改范围:
- 小范围修改:例如调整人物表情、改变颜色、微调物体形状。
- 大范围替换:如修改场景背景、增添新的物体、或替换整个主题元素。
- 例子:用户可以要求 SeedEdit “将图中的普通街道替换为樱花大道”,SeedEdit 将会自动调整树木和花朵细节,营造出新的视觉效果,而不改变原图的总体风格。
- SeedEdit 能够处理许多常见的图像编辑任务,比如:
- 局部替换:替换图片中的某个元素,比如把图中的兔子替换成小鹿。
- 几何调整:调整图像中物体的大小、形状或角度,比如让人物转向一侧或改变手的位置。
- 光线变化:调整光照的方向和强度,比如让光线从左侧照射进来。
- 风格转换:将图像转变成不同的艺术风格,比如把现实风格变为卡通风格。
- SeedEdit 支持多种类型的编辑,涵盖从微小细节调整到大范围内容替换的各种需求,能够处理不同的修改范围:
下面是我测试的一些案例:

换头术:一句话更换人物的头部,其他保持不变

改变人物表情,让他眯眼微笑

用中文提示词输入,要求它将welcome单词改为再见
它竟然自己识别出来我的意思
然后把英文替换了
可惜的是目前还不支持中文

保持人物主体不变,更改人物的背景、服装颜色以及灯光,效果炸裂

将白天变为晚上

把图像中的特定物体替换掉,毫无违和感
SeedEdit 的工作原理
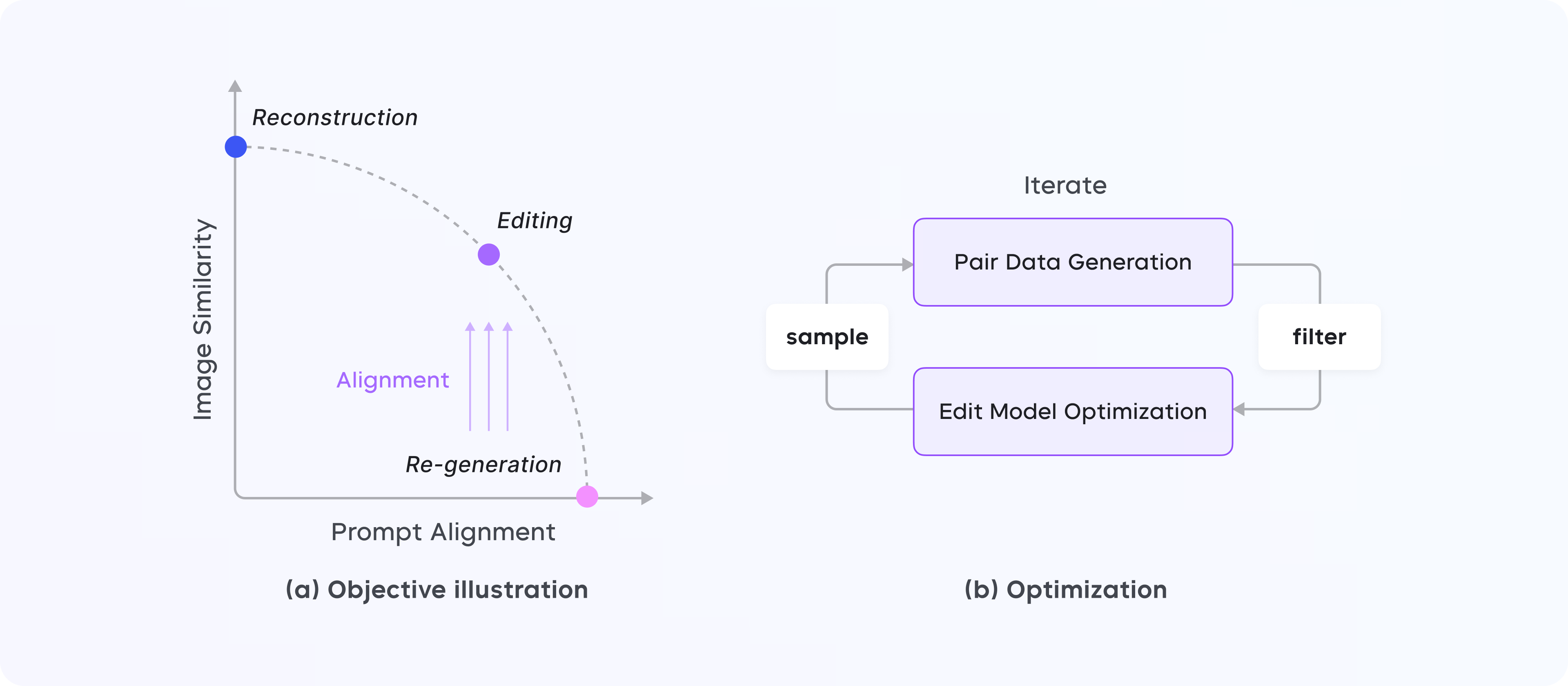
SeedEdit 的核心目标是平衡图像重构和再生成,即在保持原始图像信息的同时,灵活地根据文本指令进行修改。为此,SeedEdit 提出了一种基于渐进式对齐的框架,将预训练的文本到图像(T2I)模型转化为能够精准编辑图像的扩散模型。
SeedEdit 的整体解决方案分为三个主要步骤:
- 构建多样化的编辑数据集:使用 T2I 模型生成丰富的图像对数据集,用于不同编辑任务的训练。
- 因果扩散模型的双分支架构:通过自注意力机制实现图像输入与文本指令的对齐,使得编辑任务在保持图像一致性的前提下完成。
- 迭代式微调与对齐:通过多轮优化,逐步提升模型的编辑一致性和成功率。
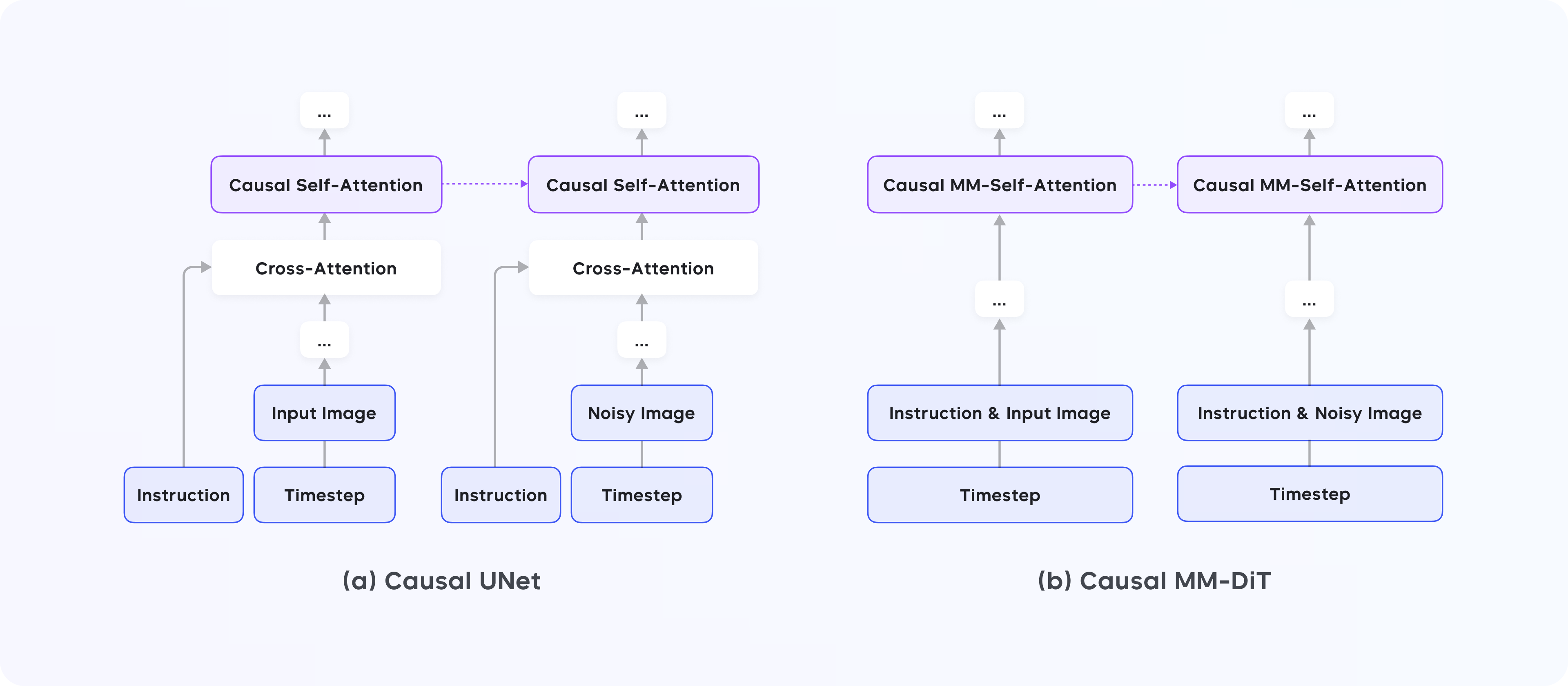
因果扩散模型(Causal Diffusion Model)
- 概述:SeedEdit 的核心是一个因果自注意力扩散模型,这一模型结构允许图像编辑时使用文本指令作为条件输入,确保编辑的内容符合用户的描述。它可以根据不同的编辑需求进行细化操作。简单来说,SeedEdit 能够在不影响其他图像部分的情况下,精确地修改指定区域,确保图像质量不受影响。
- 模型架构:模型有两个主要分支,分别处理输入图像和生成目标图像。这两个分支共享相同的参数,通过自注意力机制进行通信。
- 工作原理:在编辑过程中,模型会生成一个中间特征层,使输入图像和文本描述之间能够进行信息交换,从而实现图像的定向修改。
- 优势:这种设计不仅能保持图像的一致性,还能避免因添加额外参数而导致的模型复杂化,减少训练资源的消耗。
 SeedEdit 实现这些效果的核心原理在于两个步骤:
SeedEdit 实现这些效果的核心原理在于两个步骤:
- 图像数据生成和过滤:通过大量的图像和文字数据训练模型,让 SeedEdit 学会理解“编辑”是什么意思。它可以根据不同的需求生成和挑选出高质量的数据,以便在多种编辑任务中表现出色。
- 智能编辑架构:SeedEdit 的架构专门针对编辑任务进行了优化,这样用户的每一个指令都能被准确解析和执行。比如输入“把他闭上眼睛微笑”,SeedEdit 会先理解这个指令的含义,再定位到人脸的区域进行处理,最终生成符合描述的图像。
技术方法
1、数据生成
问题:大规模且多样的图像编辑数据集难以获取。
解决方法:
- SeedEdit 使用一个已经训练好的文本到图像模型(T2I),生成成千上万对图像数据,其中包含编辑前和编辑后的图片。
- 为了让数据更丰富,SeedEdit 使用不同的编辑技术来生成多种不同类型的图像对,这样一来,训练数据就能够覆盖多种编辑需求。
- 最后,筛选出高质量的图像对,确保用于模型训练的数据足够清晰且多样。
2、因果扩散模型的双分支架构
问题:如何在编辑时保持图像的原始信息不被破坏?
解决方法:
- SeedEdit 的模型采用了双分支结构,分别接收输入图像和文本指令。这个架构就像让模型有了“左右手”,一只手负责原始图像,另一只手负责指令,这样模型可以“同时理解”图像和指令。
- 双分支结构还使用了“因果自注意力”技术,这意味着模型在编辑过程中可以逐步调整图像的细节,避免丢失原有信息。
- 当没有图像输入时,SeedEdit 可以像普通的文本到图像模型一样生成新图像,这使得它能够灵活处理多种任务。
3、迭代优化
问题:模型在处理多种编辑任务时,如何保证准确性和一致性?
解决方法:
- SeedEdit 通过多轮微调逐步提升模型的编辑能力。在每一轮优化中,模型会生成新的编辑数据,再从中挑选质量高的样本继续优化。
- 每轮的筛选和训练帮助模型不断“积累经验”,适应更多不同的编辑需求,从而变得更加稳定和鲁棒。
- 这个过程持续进行,直到模型的表现稳定为止。
评估结果
在 HQ-Edit 和 Emu Edit 两个数据集上的表现:
- HQ-Edit 数据集:
- SeedEdit (SDXL 模型):CLIP 方向得分为 0.1656,图像相似度为 0.8698,GPT 评估得分为 71.24。
- SeedEdit(自家 T2I 模型):方向得分达 0.1766,相似度为 0.8524,GPT 评分达 78.54。
- 对比方法:SeedEdit 的表现大幅超越了 Instruct-Pix2Pix、MagicBrush、UltraEdit 等其他方法,显示出更高的编辑准确性和一致性。
- Emu Edit 数据集(较为复杂的真实图像编辑):
- SeedEdit (SDXL 模型):CLIP 方向得分为 0.1162,图像相似度为 0.8025,GPT 评估得分为 66.48。
- SeedEdit(自家 T2I 模型):方向得分为 0.1137,相似度为 0.7875,GPT 评估得分为 75.03。
- 对比方法:虽然 SeedEdit 在真实场景图像上的表现稍逊于在合成图像上,但仍超过了大多数方法,说明其在不同类型图像上的适应能力较强。
与商业编辑工具的对比
SeedEdit 还与 DALLE3 和 Midjourney 等商业图像编辑工具进行了比较:
- DALLE3:更符合文字提示的要求,但容易引入意外的内容改动。
- Midjourney:在美学方面表现优异,但对文字指令的准确性稍差。
- SeedEdit:在保持原始图像细节的同时实现了较高的指令准确性,整体上能更精确地编辑图像内容,且不易出现过多的无关修改。

优劣势
- 优势:SeedEdit 在图像一致性和文字指令匹配方面表现优越,尤其在合成图像编辑上取得了显著优势。
- 劣势:在真实场景图像的编辑上,SeedEdit 的表现稍逊于合成图像,但总体上仍优于大多数竞品。
- 总体评价:SeedEdit 在多项评估指标上优于现有的其他图像编辑方法,特别是在需要精确编辑的任务中表现出色,是一种稳定、准确的图像编辑解决方案。
项目地址:https://team.doubao.com/en/special/seededit
技术报告:https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/SeedEdit.pdf
在线演示:https://huggingface.co/spaces/ByteDance/SeedEdit-APP
-
豆包 Web:https://www.doubao.com/chat/create-image -
即梦 Web:https://jimeng.jianying.com/ai-tool/image/generate













{kind=link}