

马斯克X AI发布Grok-1.5 Vision 多模态模型
Grok-1.5V能够处理文本以及各种视觉信息,包括文档、图表、截图和照片。
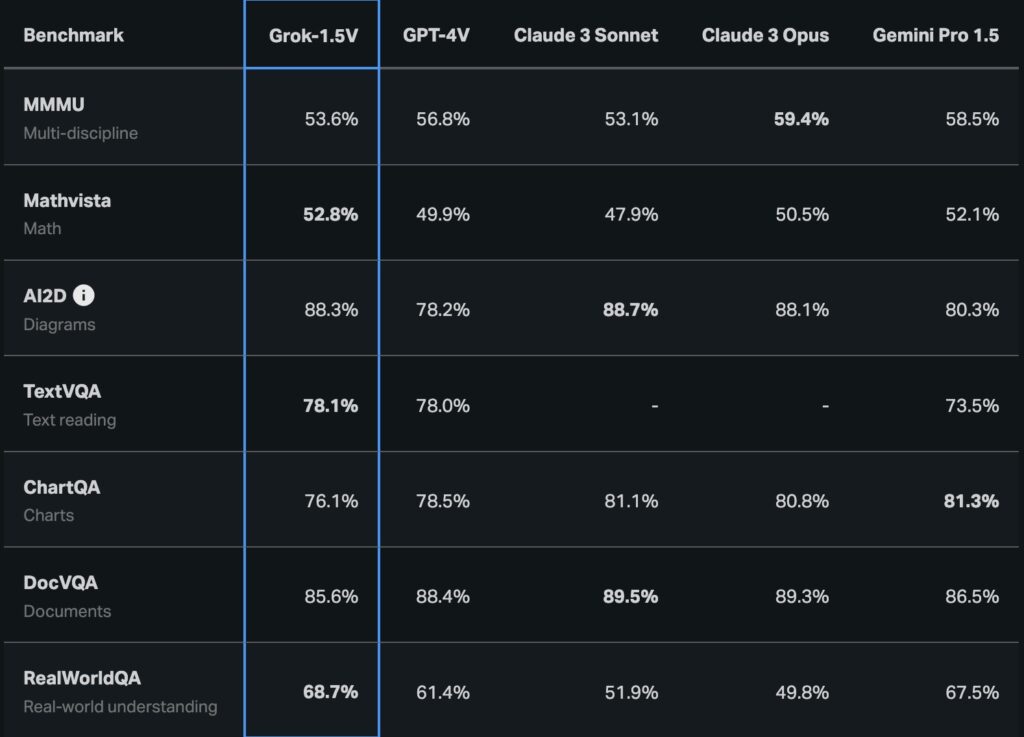
基准测试中,Grok-1.5V 的能力和GPT 4V不相上下,多项指标甚至超过GPT 4V!
在新RealWorldQA真实世界物理空间基准中的表现超过GPT 4V等所有模型!
应该是使用了特斯拉的摄像头数据进行了训练!
RealWorldQA基准:这是一个新的基准测试,旨在评估多模态模型在理解真实世界物理空间方面的能力,包含超过700个问题和答案,主要采用来自车辆前摄像头等实际环境中的图像。
Grok-1.5V将很快向早期测试者和现有Grok用户开放。
关键能力点列出:
- 多学科推理: Grok-1.5V在多学科推理领域表现突出。
- 理解文档和科学图表: 能有效理解科学图表、文档等复杂视觉资料。
- 实际应用中的表现: 在RealWorldQA基准测试中,Grok-1.5V表现优于多数同类模型,展现了对现实世界问题的理解能力。
数据表现对比:
- 多模态推理 (MMMU): Grok-1.5V的表现为53.6%,相比其他模型如GPT-4V的56.8%稍低。
- 文本视觉问答 (TextVQA): 在文本读取能力上,Grok-1.5V与GPT-4V持平,均为78%。
- 图表视觉问答 (ChartQA): 在图表理解上,Grok-1.5V的表现稍低于竞争对手,为76.1%。
- 文档视觉问答 (DocVQA): 在文档理解上,Grok-1.5V表现为85.6%,略低于GPT-4V的88.4%。
- 真实世界理解 (RealWorldQA): 在真实世界的空间理解上,Grok-1.5V以68.7%的成绩领先大多数模型。
Grok团队计划在未来几个月内,对模型的多模态理解和生成能力进行重大改进,扩展到图像、音频和视频等不同的模态。













{kind=link}