
Suno 发布了一项新功能,允许用户从任何声音创建歌曲。所有专业版和高级版用户现在可以上传或录制音频,并将其转化为音乐。Suno希望用户在日常生活中的各种声音中找到灵感,并用新功能制作音乐。
这项新功能可以将日常生活中的各种声音转化为音乐,为音乐创作带来了新的可能性。 你只需要敲击出节奏,Suno 会自动捕捉然后与你“和弦”,哈哈…
例如:将敲击浇水壶的声音转化为迷幻摇滚音乐。
- 该功能目前对专业版和高级版用户开放。
- 用户可以录制或上传音频/视频剪辑(6-60秒)。
- Suno强调尊重版权和隐私,受版权保护的作品将被阻止上传。
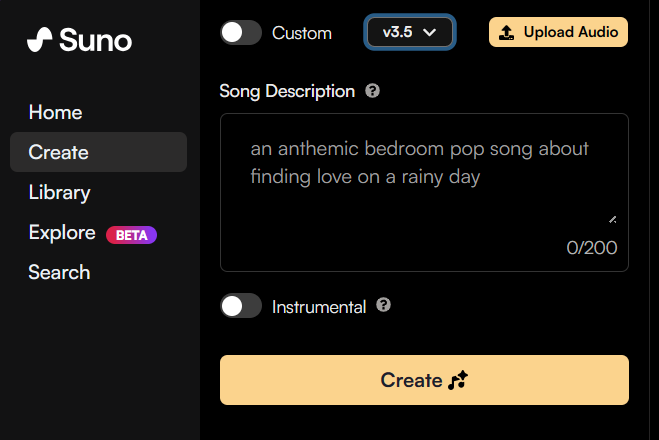 如何使用我们的新音频输入功能:
如何使用我们的新音频输入功能:
- 导航到“Library库” – 在右上角点击“Upload audio上传音频”
- 您可以录制音频或上传音频/视频剪辑。剪辑应在6-60秒之间
- 上传后,从上传的剪辑中选择“extend扩展”。选择一个时间戳来扩展,提供一个流派,如果需要,可以包含您自己的歌词
 一些案例
一些案例
用任意声音创作歌曲![]()
VOL-2:古典钢琴,并加入一些法国手风琴 由 Anessa(钢琴家兼 Suno 软件工程师)表演
VOL-3:哼着曲子,但赋予它 R&B 氛围 由 Rebecca (Suno 产品经理) 演唱
VOL-4 Connor Yates 提供的节拍!来自乐队@lenagardeniaband 和@tower_atl 创作的作品
VOL-5 乱哼的歌
VOL-6
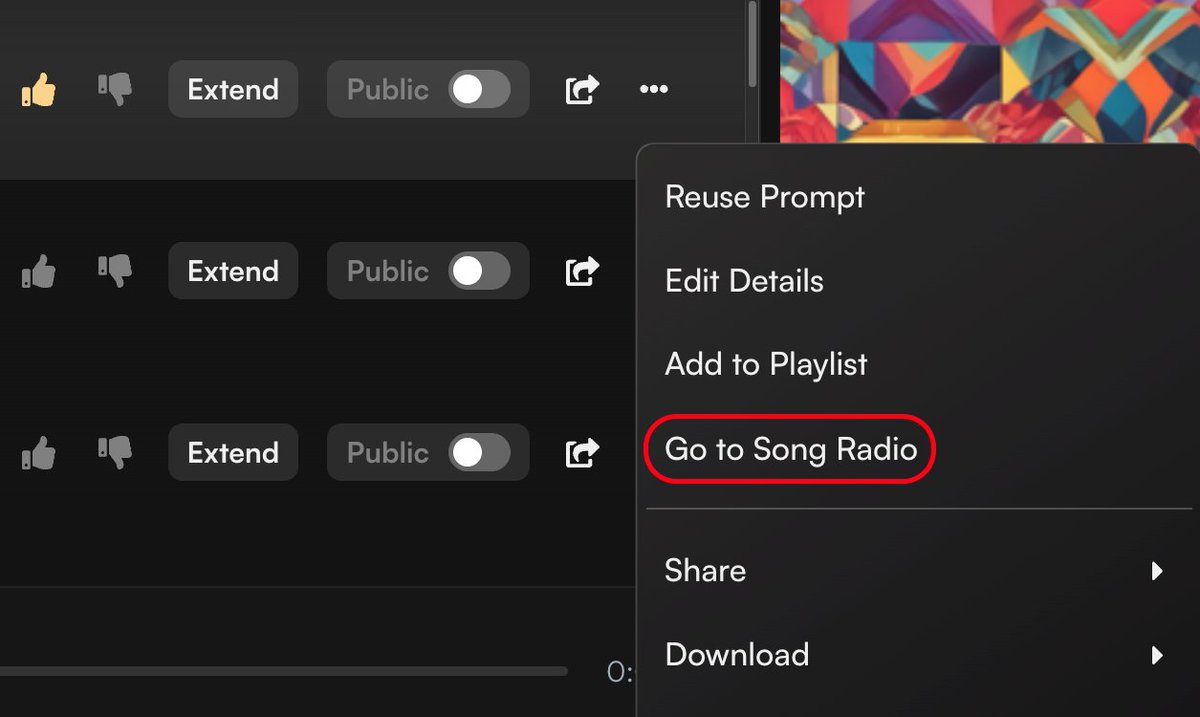
Suno还发布了一个电台功能
可以根据你的音乐偏好享受个性化播放列表,为你量身定制无尽的音乐流













{kind=link}