
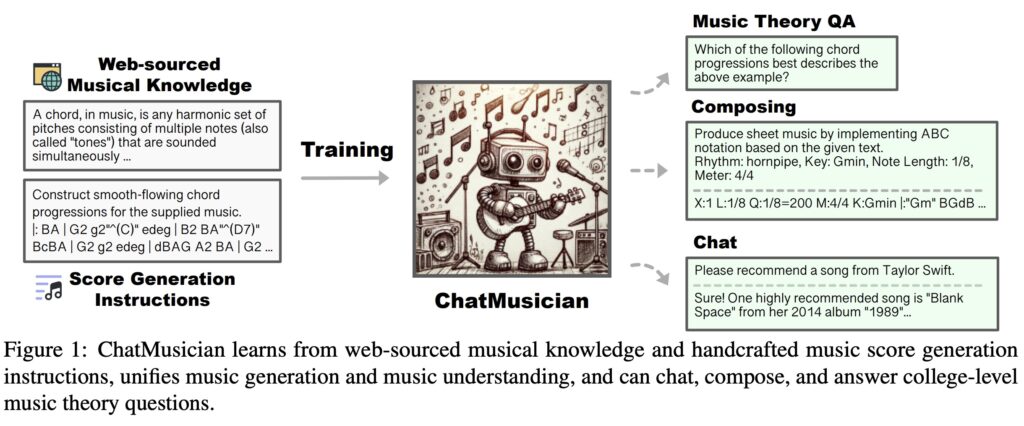
主要功能
-
音乐生成: ChatMusician能够根据给定的文本提示、和弦序列、旋律线索、音乐主题或形式等条件,自动生成结构完整、风格多样的音乐作品。这包括单声部旋律、和声编配,乃至完整的乐曲结构设计。性能超过GPT-4基线。
-
音乐理解: 该模型不仅能创作音乐,还能理解和分析音乐理论的各个方面,如和声分析、旋律结构、音乐形式等。这使得ChatMusician可以在音乐教育和理论分析中发挥作用。在专门设计的大学级音乐理解基准测试MusicTheoryBench上,ChatMusician在零样本设置中超过了LLaMA2和GPT-3.5,展示了其在音乐理论理解方面的优异性能。















{kind=link}