
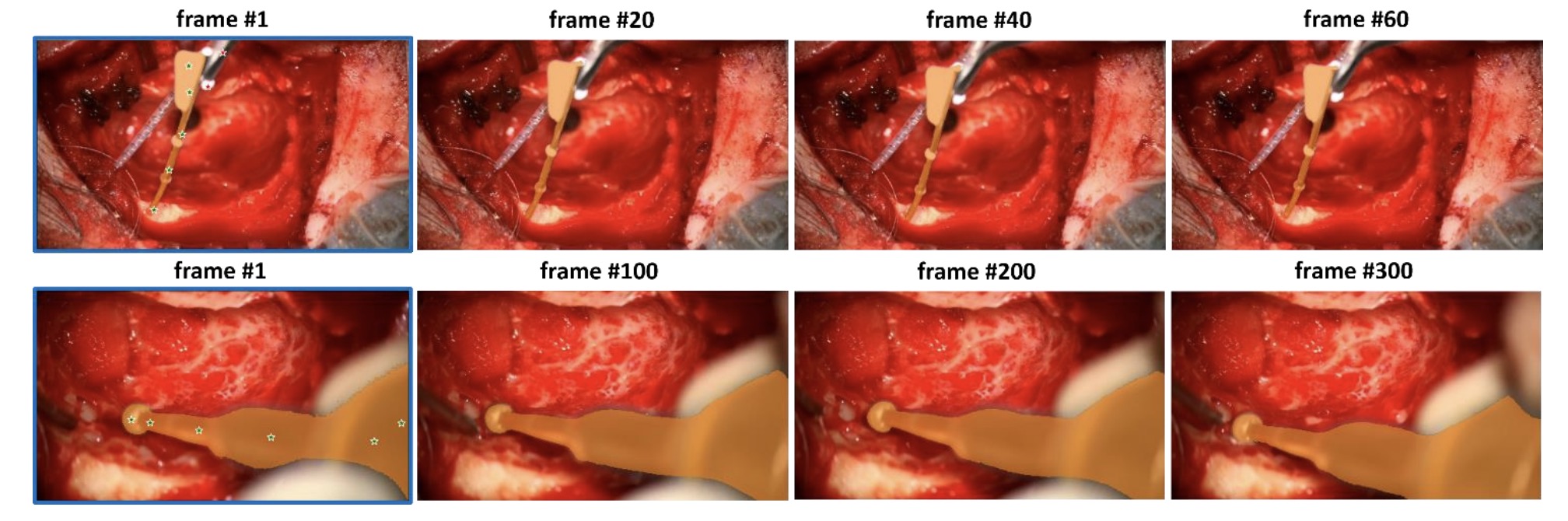
研究人员使用了Meta AI 的 Segment Anything Model 2 (SAM 2) 来评估其在不同类型的外科手术视频中对手术工具进行零样本分割的性能。
模型在没有预先见过这些视频或手术工具的情况下,通过少量的提示(例如在视频的第一帧中手动标记某些工具),就能够自动识别和分割视频中后续帧中的手术工具。
研究选择了不同类型的手术视频进行评估,包括:
- 内窥镜手术视频(例如通过 EndoNeRF、EndoVis’17 和 SurgToolLoc 数据集进行测试),这些视频通常是在体内使用内窥镜进行手术时拍摄的。
- 显微手术视频,例如在耳科手术(如耳蜗植入手术)中使用显微镜拍摄的手术视频。
研究表明,SAM 2 在处理内镜和显微手术视频时表现良好,能够准确分割出视频中的手术工具。不过,如果视频太长或者环境复杂(例如模糊或遮挡),模型的表现可能会有所下降。
功能特点
- 零样本分割:无需预先标注数据,SAM 2 模型可以直接从手术视频中识别和分割外科工具。通过使用提示(例如点、框、掩码),模型能够在视频的第一帧中获取信息,并将其应用到整个视频中进行工具追踪和分割。
- 多场景适用性:该工具适用于不同类型的手术视频,包括内镜手术和显微手术。它可以处理包含多个手术工具的场景,以及视频长度不同的手术过程。
- 高效分割:SAM 2 模型使用了广泛的Segment Anything Video (SA-V)数据集进行训练,能够高效地分割视频中的手术工具,减少了对手动标注的依赖,并提升了分割的精准度。
- 内置记忆库:模型集成了一个记忆库,用于在视频的帧之间传播初始提示,从而保证分割的连续性和准确性。
- 应对复杂环境:尽管存在挑战,例如模糊、遮挡和出血等复杂环境条件,SAM 2 仍能在这些情况下提供可靠的工具分割结果,并通过额外的提示进一步提升分割效果。
- 适用于实时应用:由于其零样本分割能力和记忆库的结合,该工具有潜力在实时手术场景中使用,帮助外科医生更准确地识别和追踪手术工具。
主要作用
- 提升外科手术的精度和安全性:
- 通过自动识别和分割手术视频中的工具,帮助外科医生更清晰地看到手术现场,减少了手术过程中可能的误操作,从而提高了手术的精度和安全性。
- 减少人工标注的工作量:
- 传统的手术视频分析需要大量的人工标注,而该工具的零样本分割能力可以在没有或极少人工标注的情况下直接应用,显著减少了时间和人力成本。
- 支持多样化手术场景:
- 该工具可以在不同类型的手术视频中应用,包括内镜手术和显微手术,能够适应不同工具数量和手术过程长度的变化,适用性广泛。
- 帮助医学研究与培训:
- 自动分割和识别手术工具对于医学研究人员来说是一个强大的辅助工具,能够加速手术过程的分析和研究。同时,它也可以用于医学教育,帮助医学生和年轻医生更直观地学习手术过程。
- 促进手术机器人的发展:
- 在手术机器人领域,该工具可以用于增强机器人的视觉系统,使其能够更准确地识别手术环境中的工具,从而更好地辅助医生进行手术。
- 为未来的手术AI系统奠定基础:
- 该工具的开发和应用展示了人工智能在手术过程中的潜力,未来可以进一步发展成为更智能、更自动化的手术支持系统,甚至能够实现部分自动化手术。
实验结果
在本研究中,实验与性能评估主要集中在两个方面:内镜手术数据集和显微手术数据集。研究人员使用了多个公开数据集来测试Segment Anything Model 2 (SAM 2) 在这些手术视频中的分割性能。
1. 内镜手术数据集
使用的数据集:
- EndoNeRF:包含两个手术视频片段,分别包含63帧和156帧。
- EndoVis’17:包含8个机器人手术视频,每个视频包含255帧,以及对应的地面真值(ground truth)分割掩码。
- SurgToolLoc:包含24,695个视频片段,每个片段持续30秒,以60帧每秒的速度捕获,所有视频均来自达芬奇机器人手术系统。
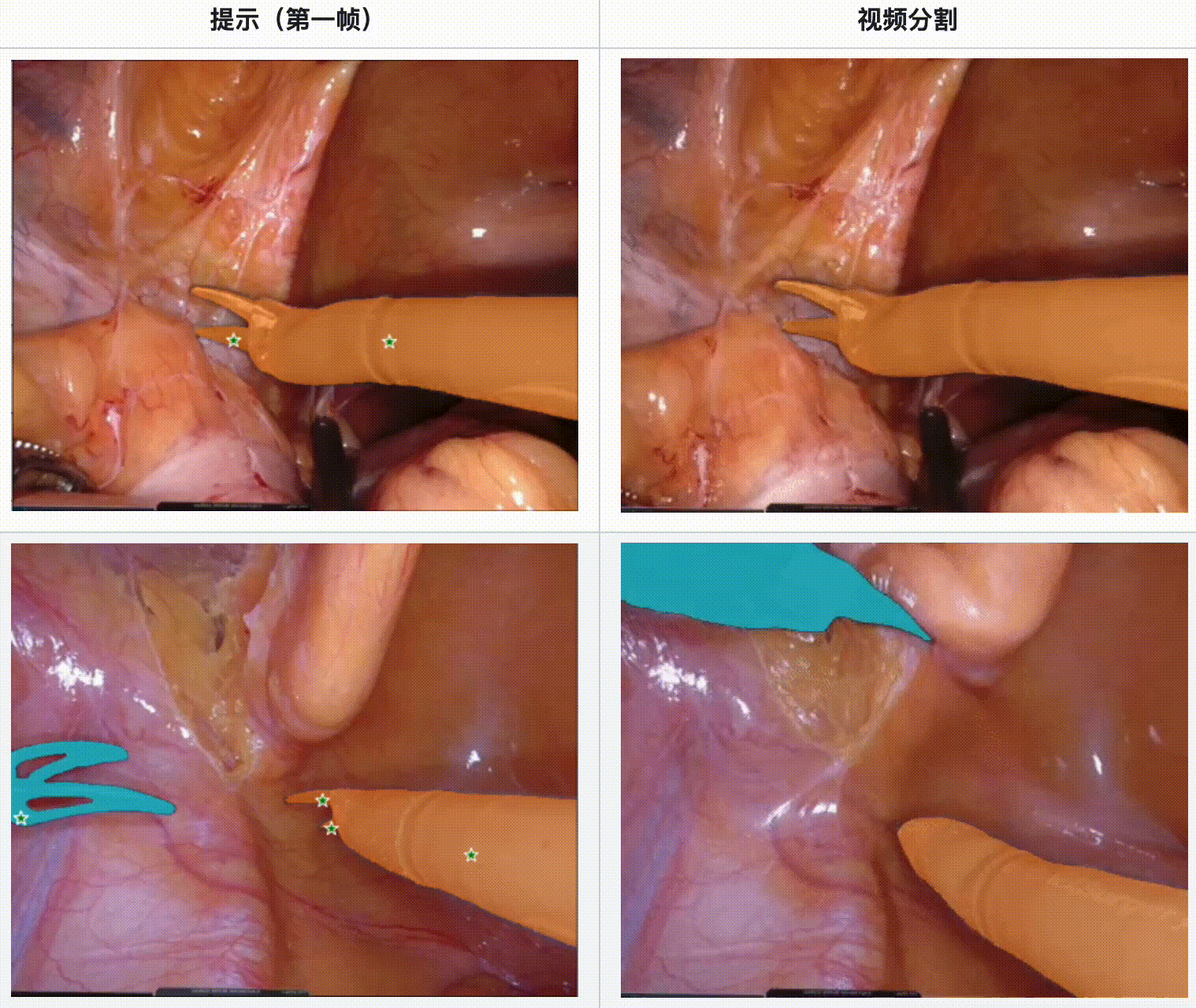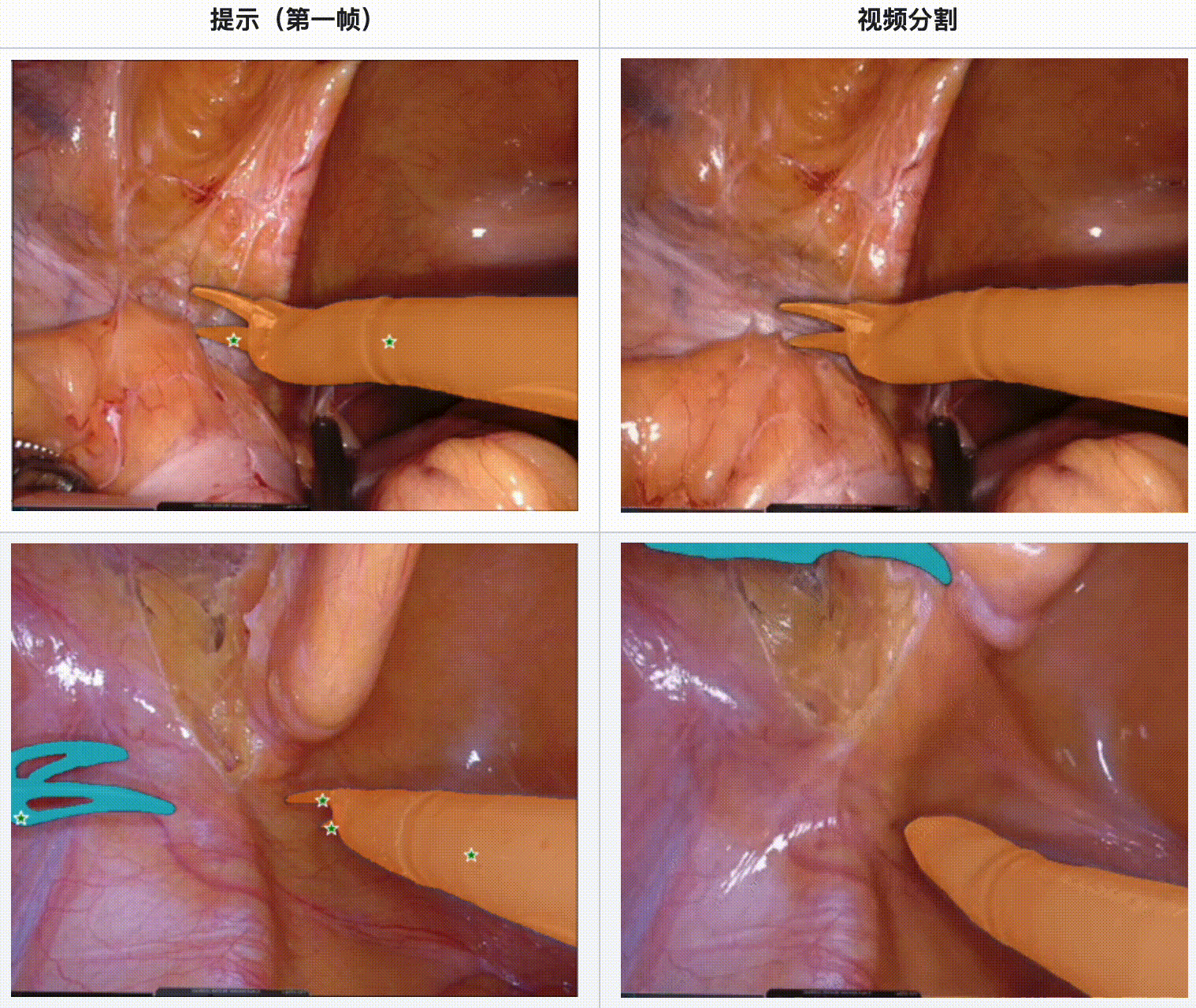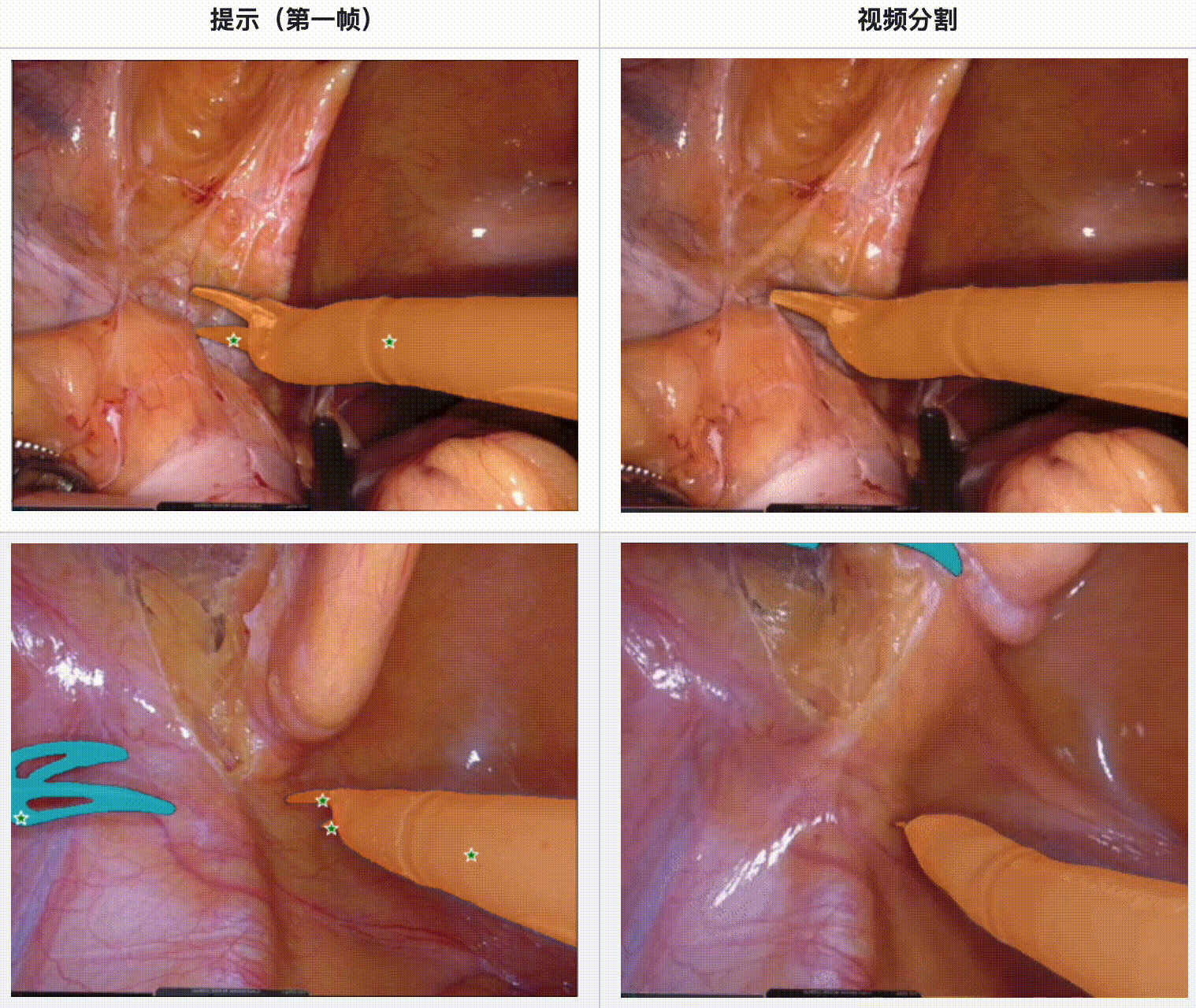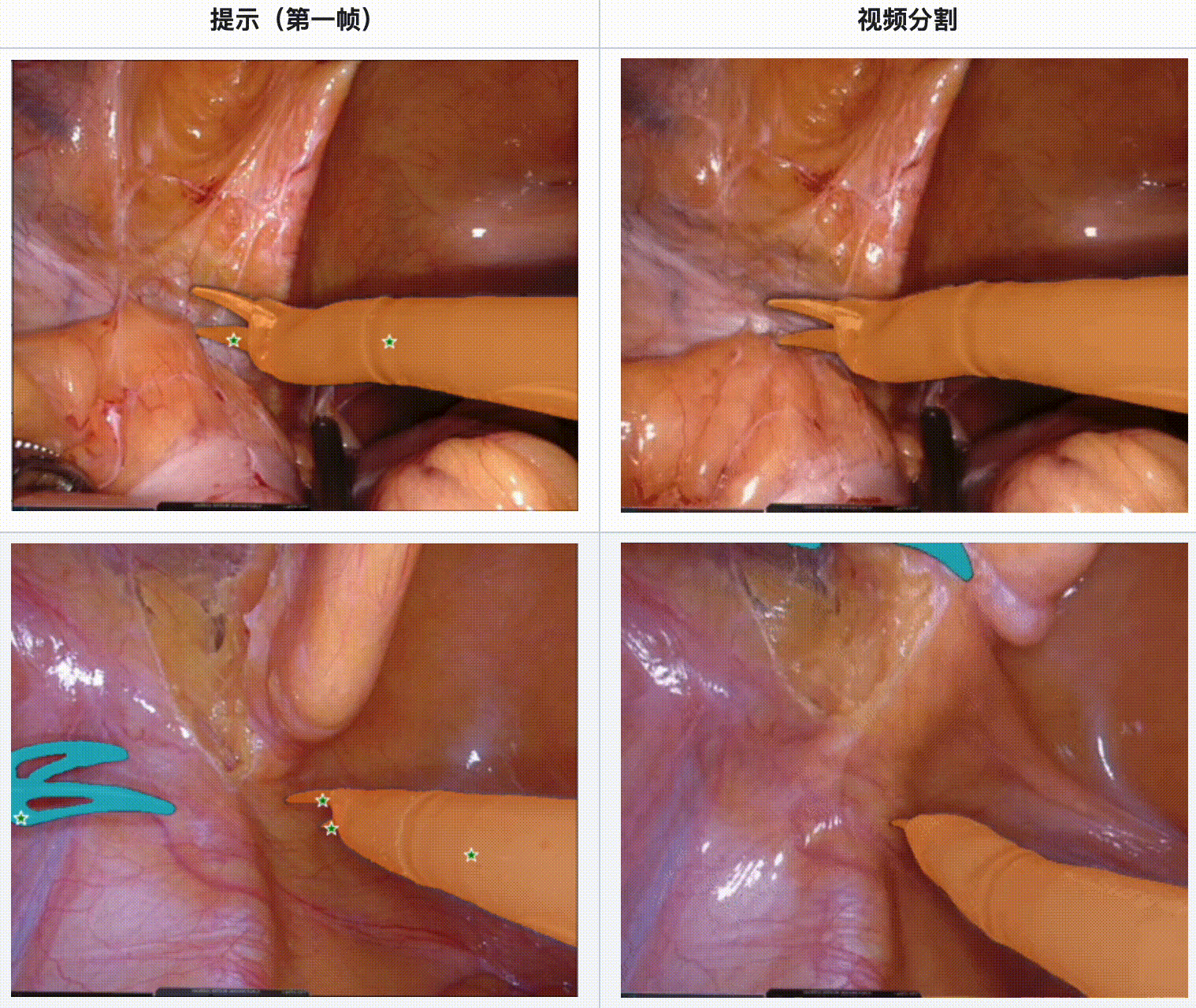
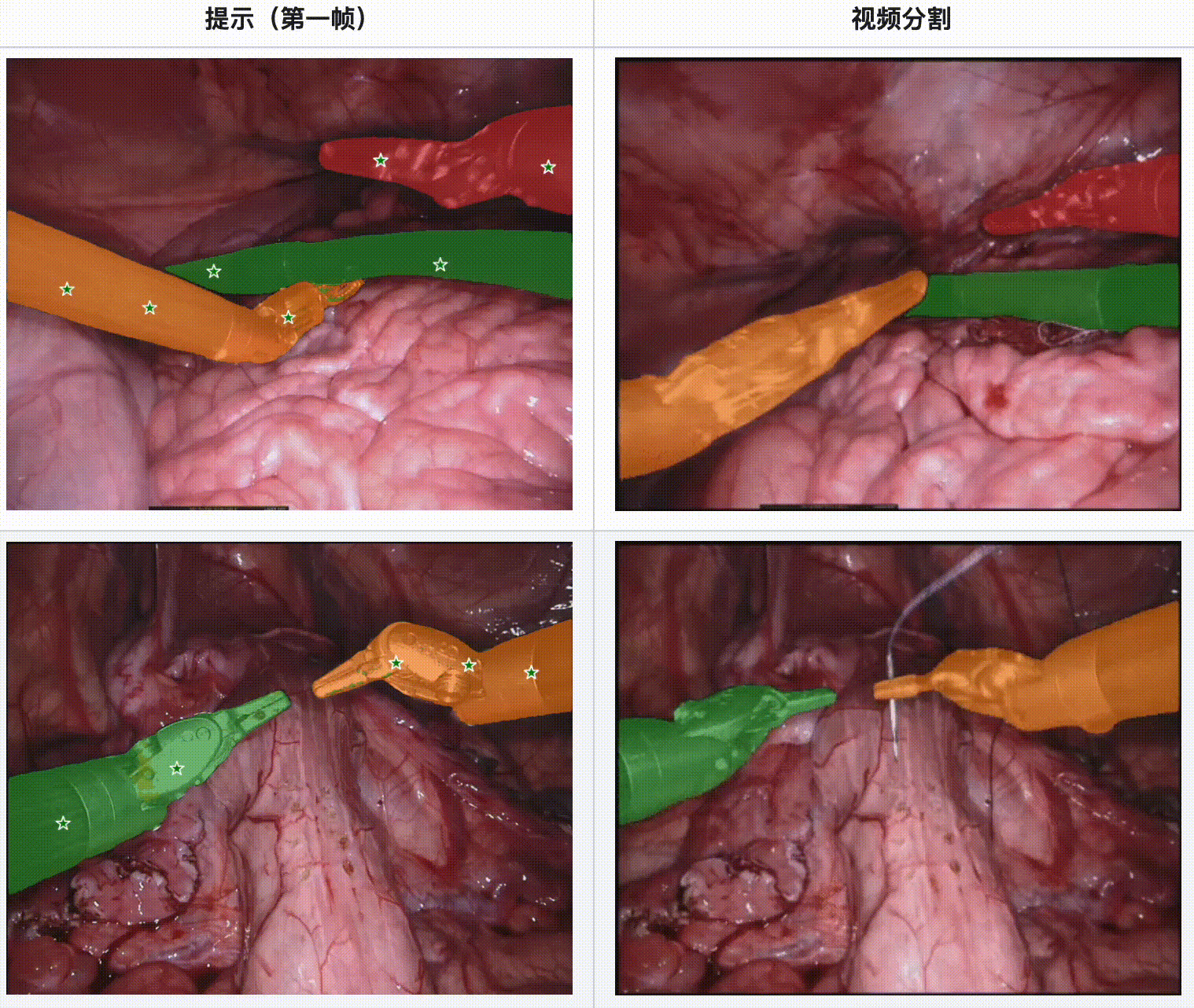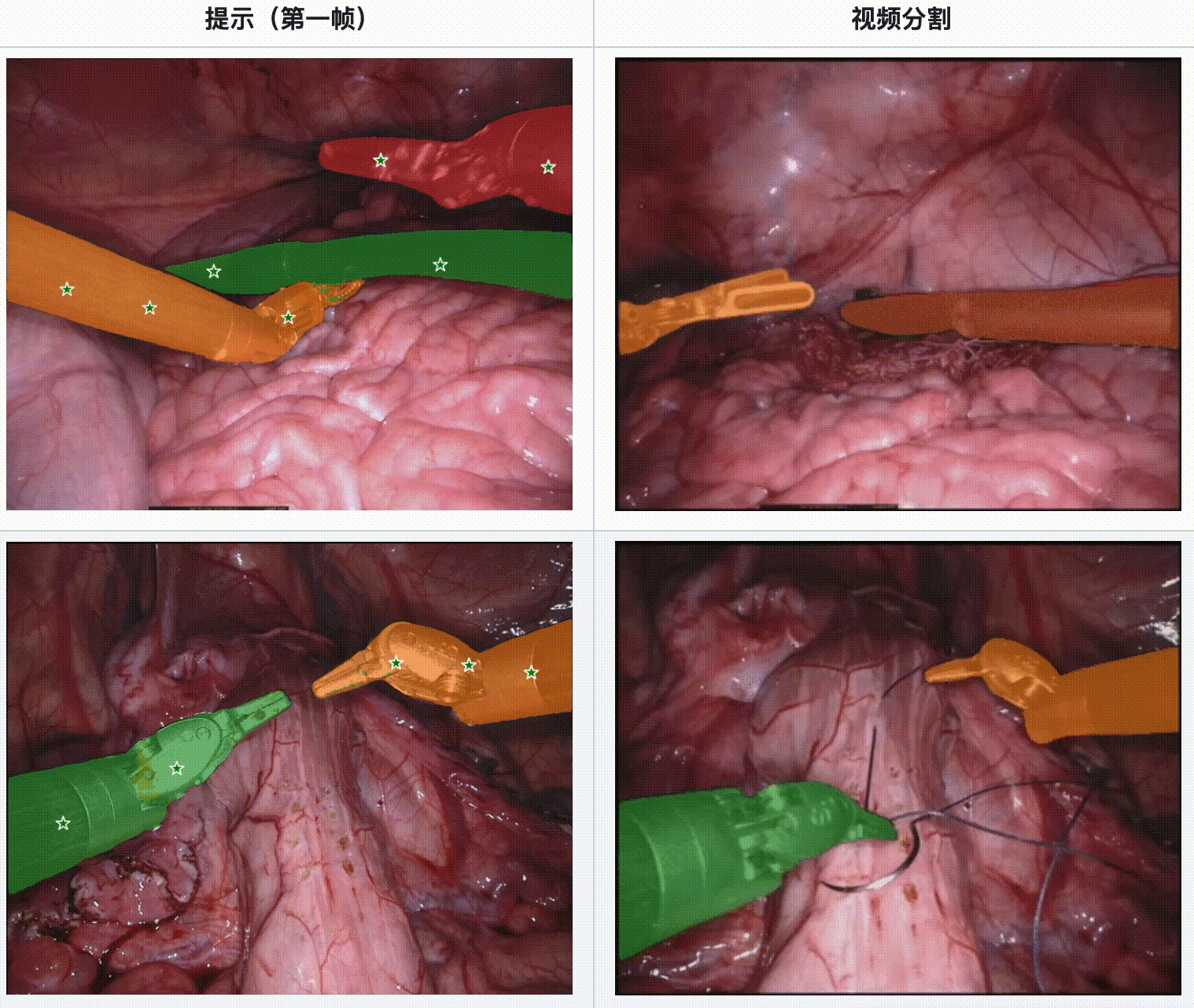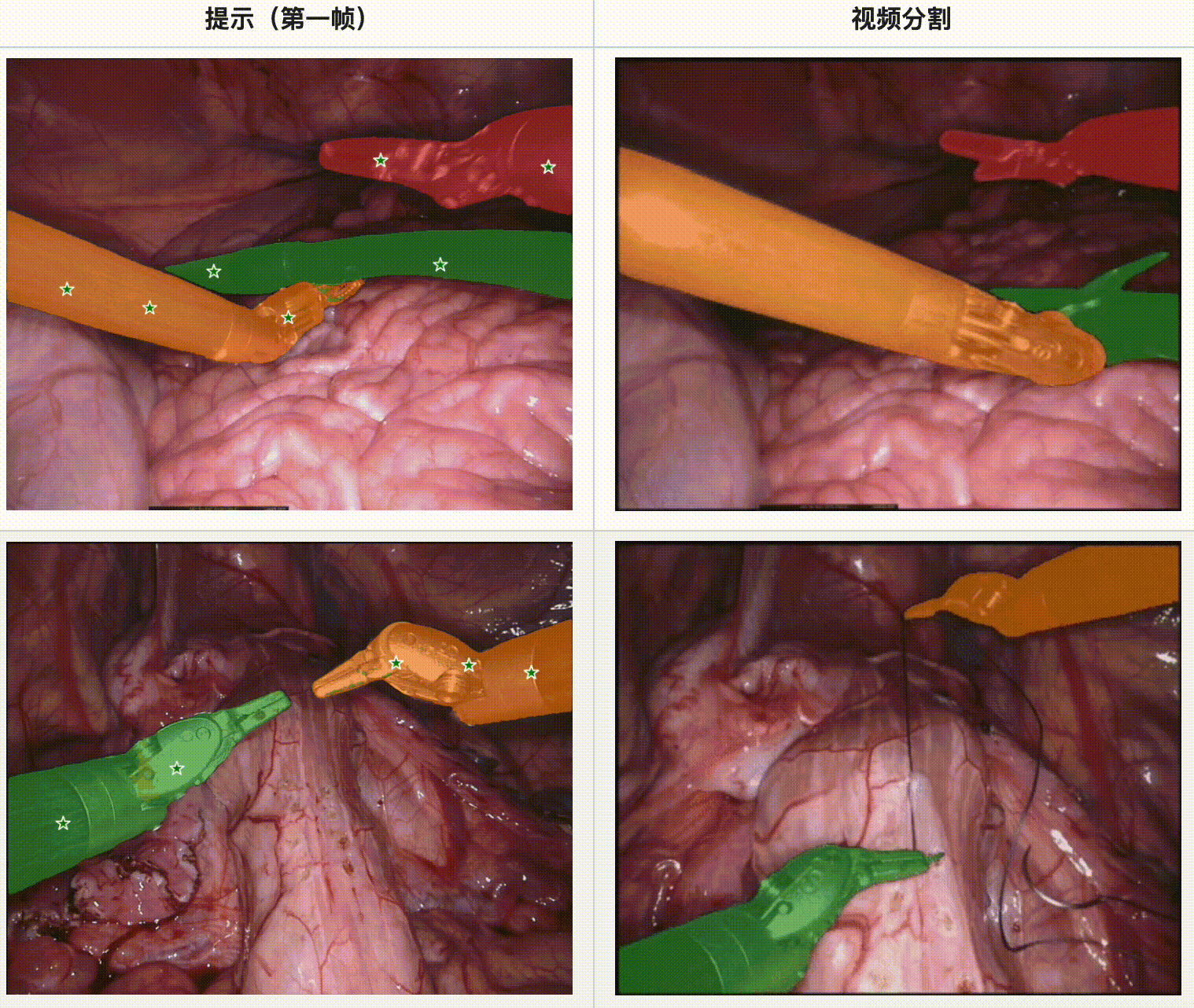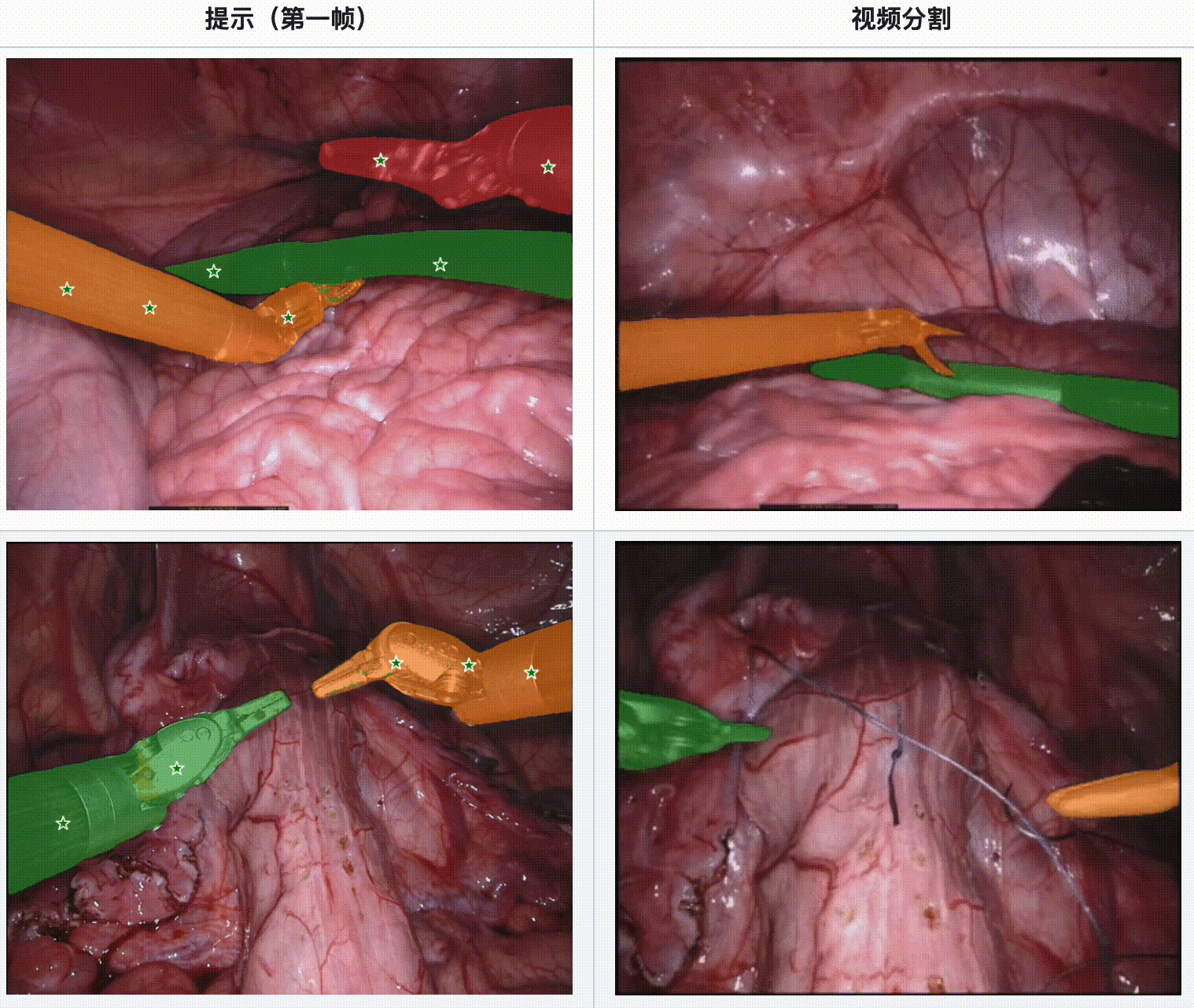
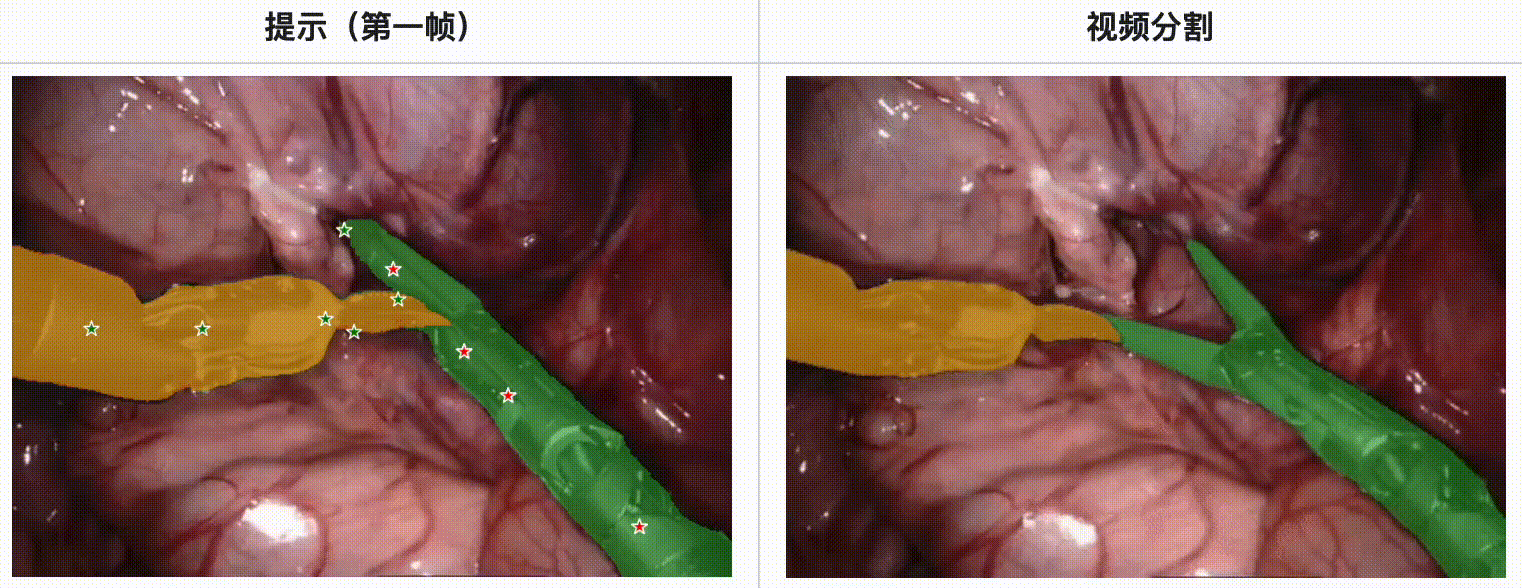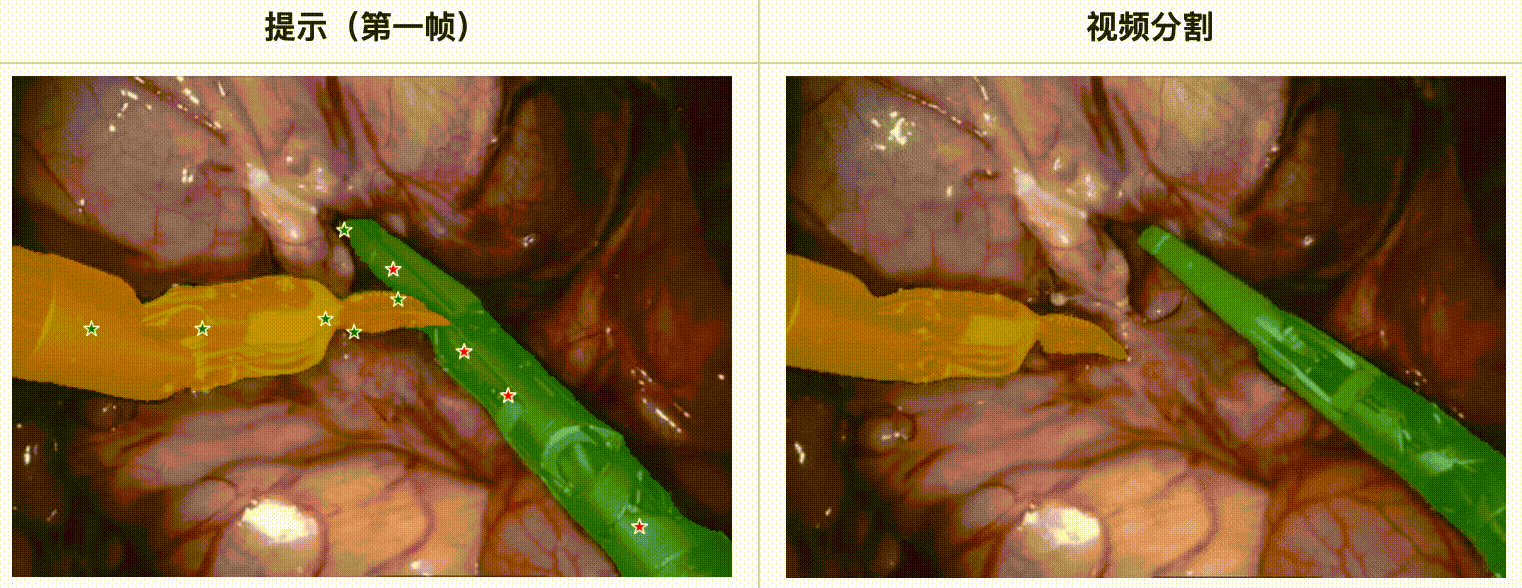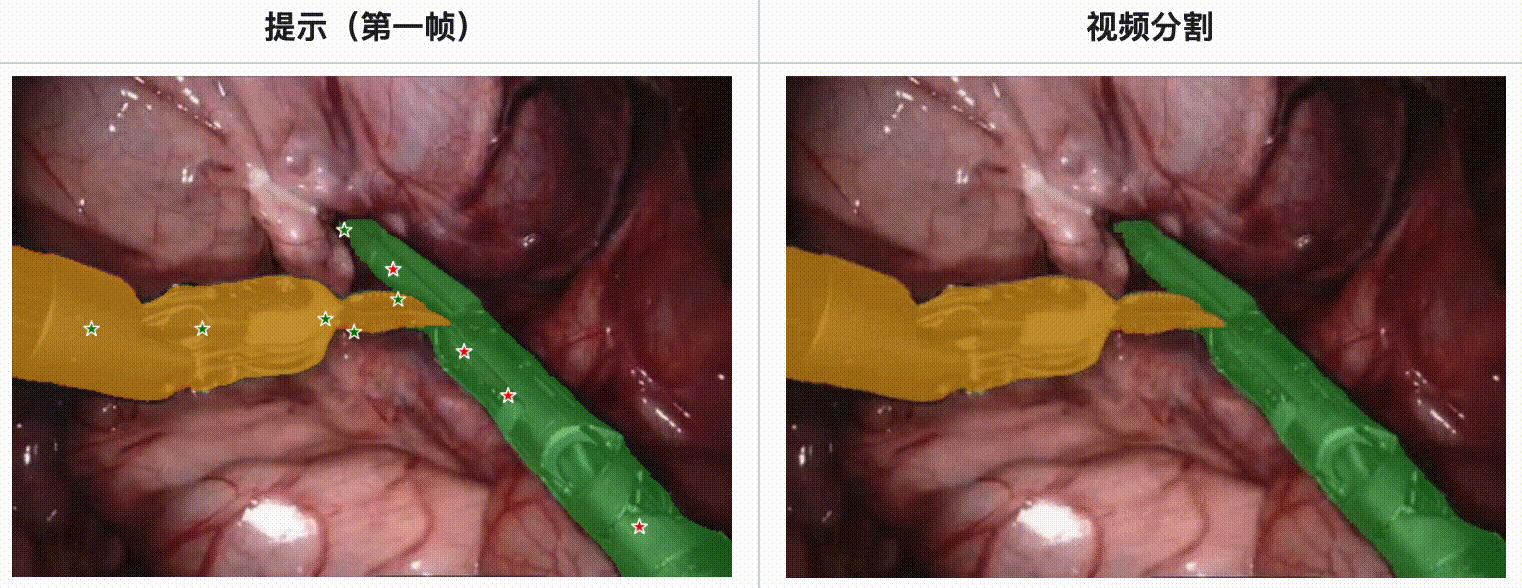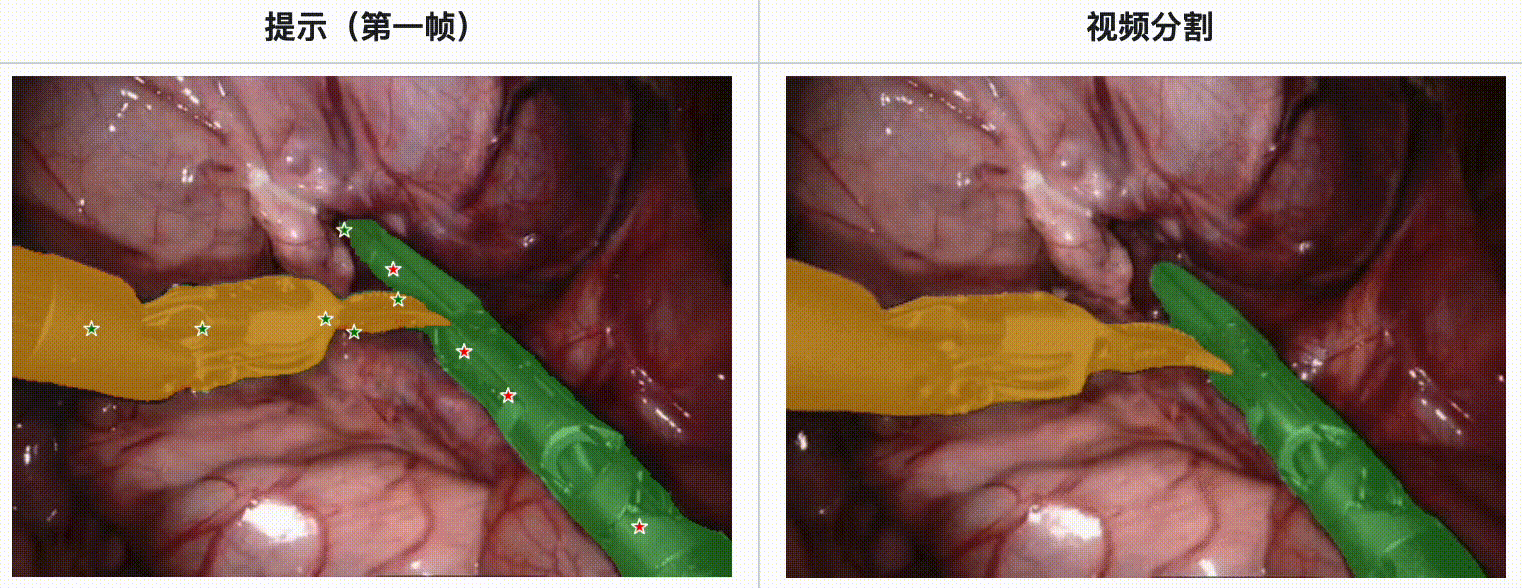 评估结果:
评估结果:
- 在内镜手术数据集中,SAM 2 展现了强大的工具分割能力,特别是在多工具场景和不同视频长度的情况下。
- 使用EndoVis’17数据集进行的定量评估表明,SAM 2 在Dice分数、IoU(Intersection over Union)和MAE(Mean Absolute Error)方面均优于其他主流分割方法,如U-Net、UNet++和TransUNet。
量化评估数据:
- Dice得分:SAM 2 达到0.937,明显高于U-Net (0.894)、UNet++ (0.909) 和 TransUNet (0.904)。
- IoU:SAM 2 的IoU值为0.890,同样优于其他方法。
- MAE:SAM 2 的平均绝对误差(MAE)为0.018,表现最佳。
2. 显微手术数据集
使用的数据集:
- 自有数据集:从范德堡大学医学中心和南卡罗来纳州医科大学收集的人工耳蜗植入手术视频,包括不同长度的手术片段(2到10秒),涵盖手术的不同阶段(如钻孔和植入阶段)。
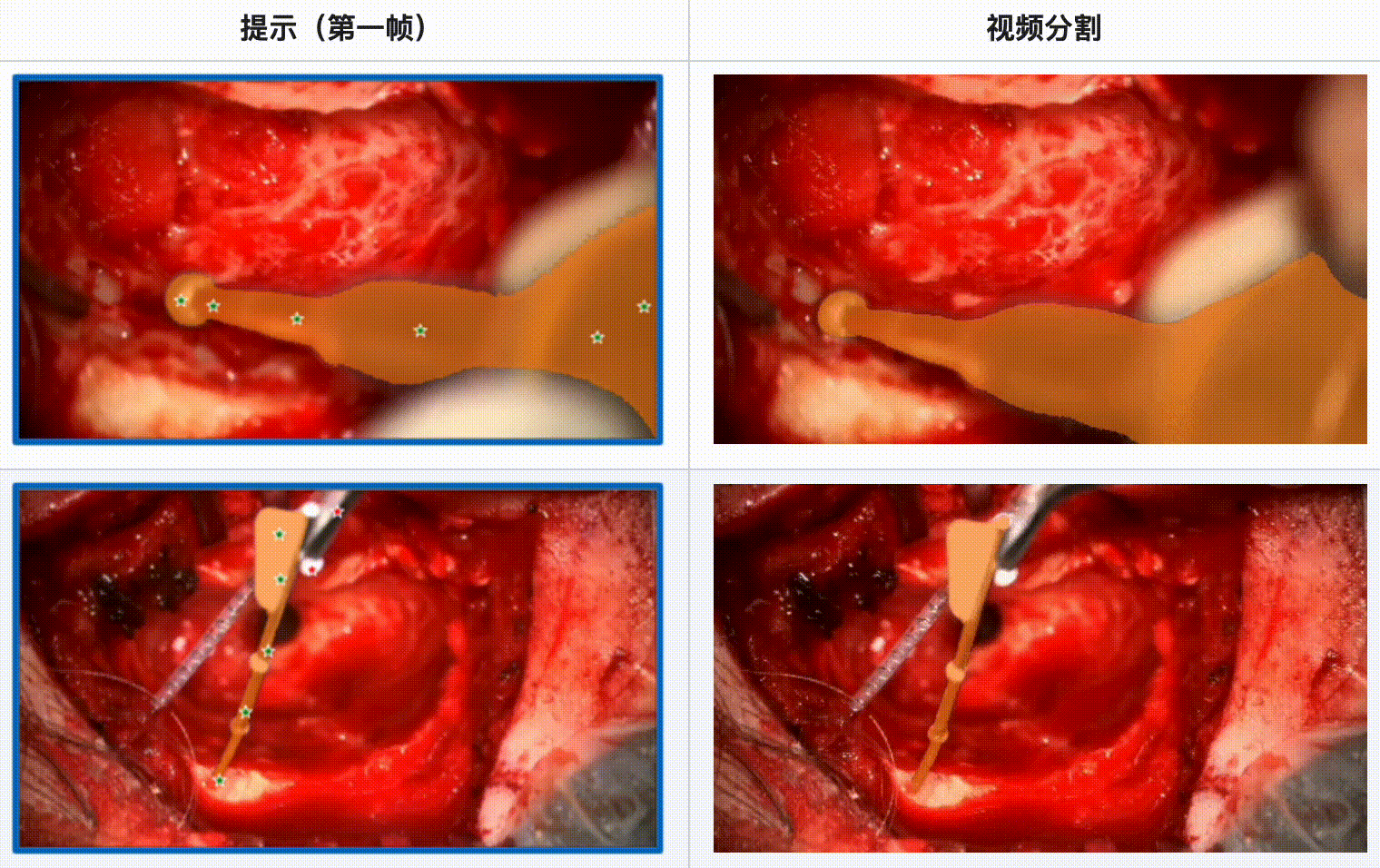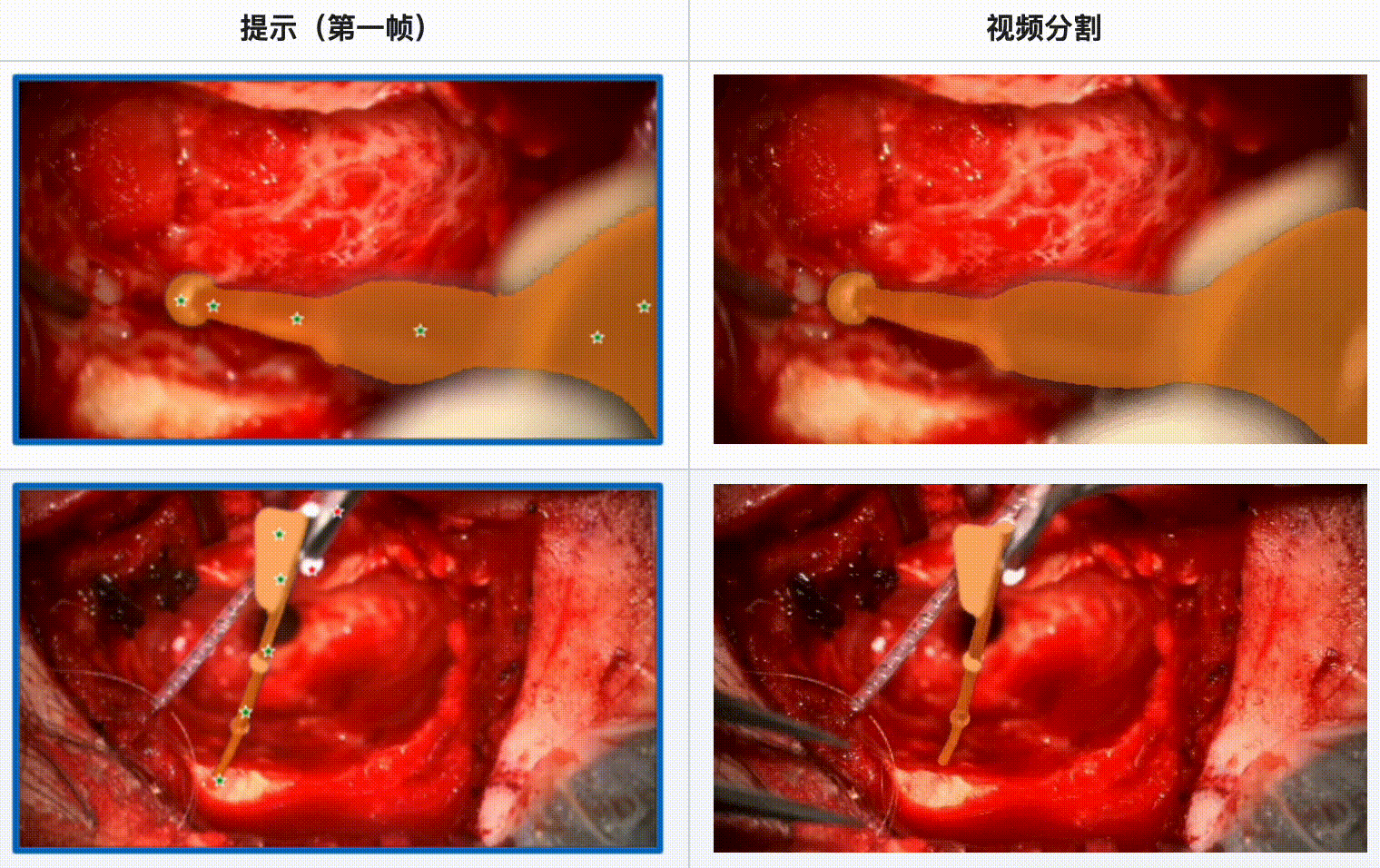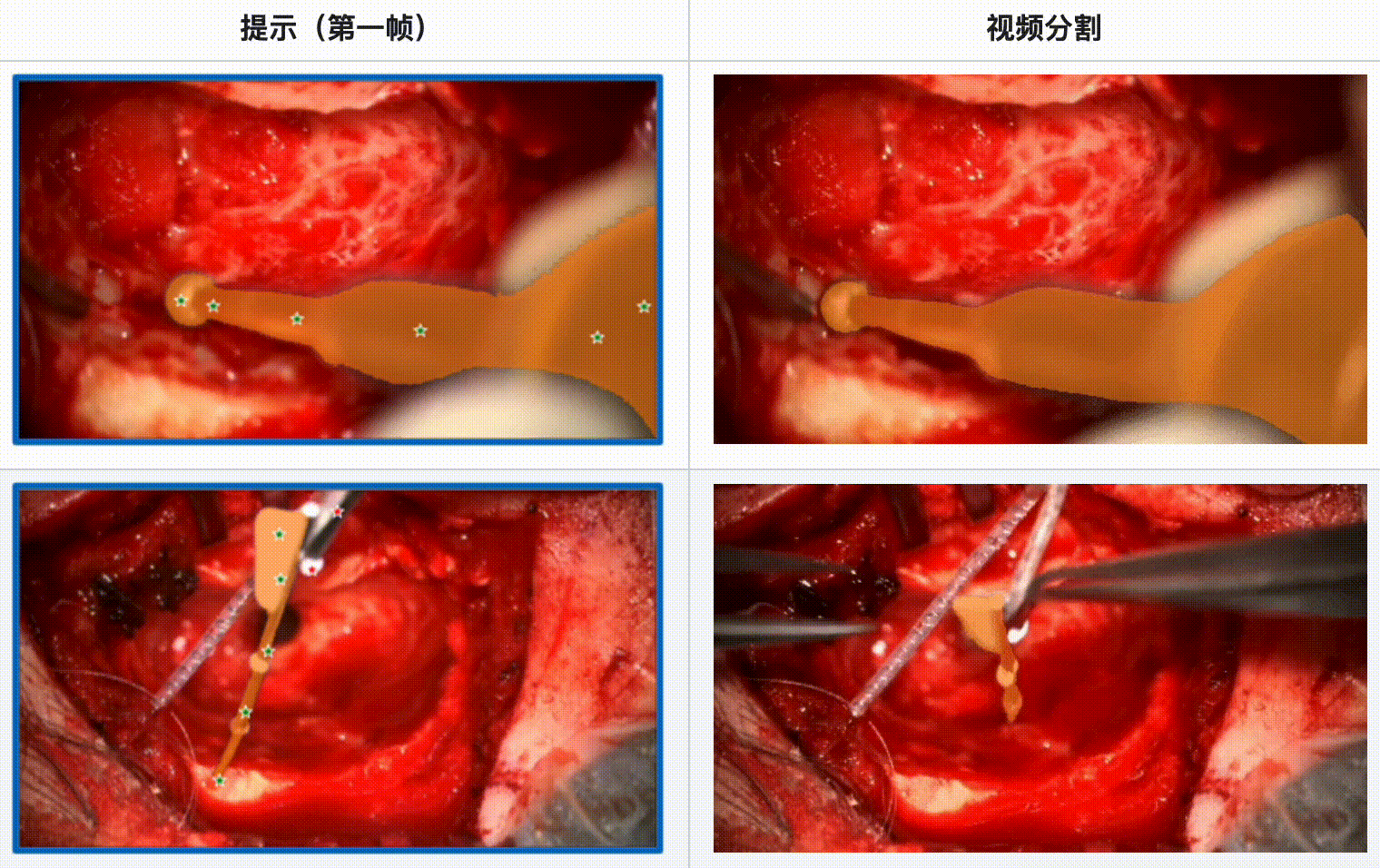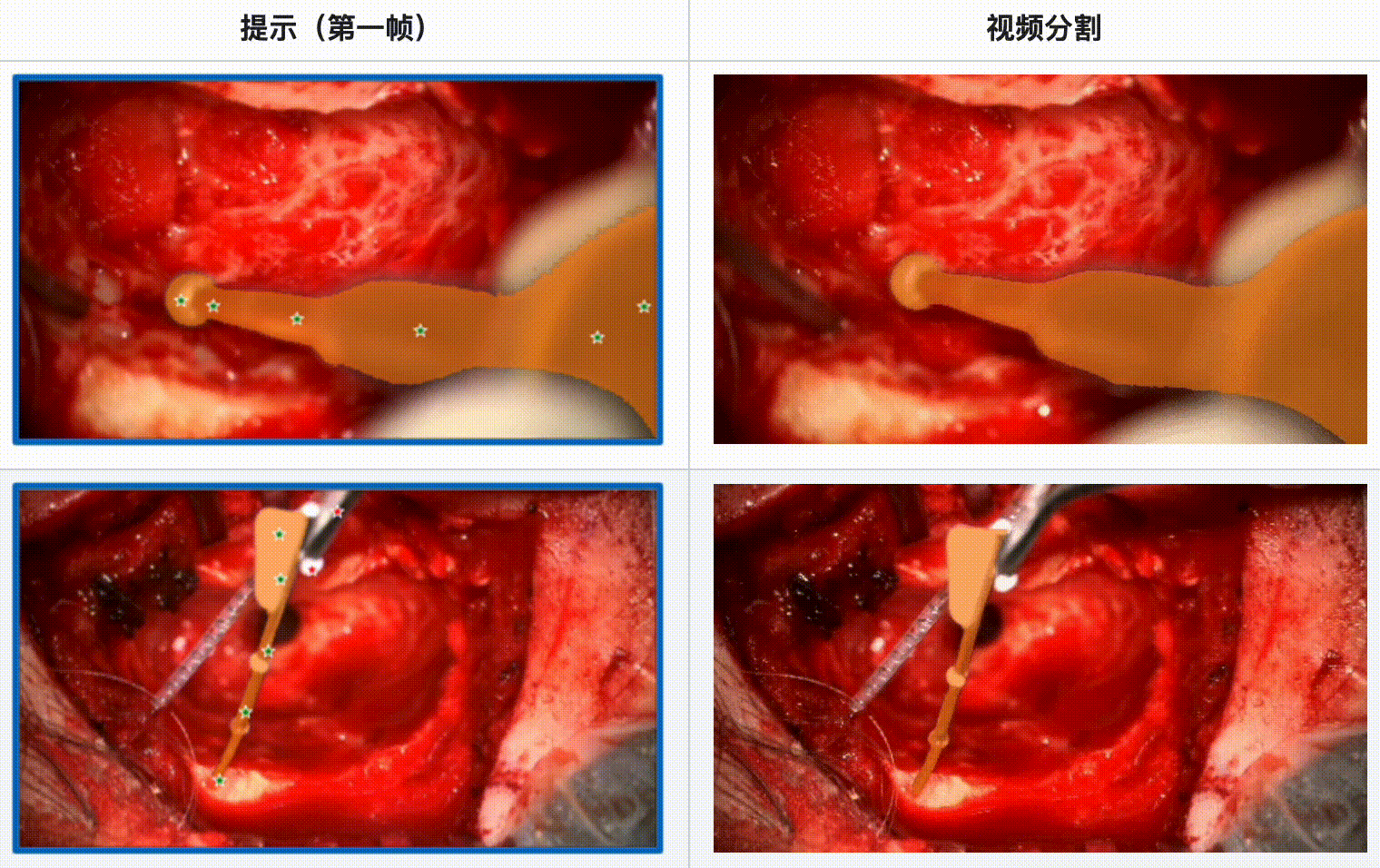 评估结果:
评估结果:
- SAM 2 在显微手术视频中表现出色,尤其是在单一工具和多工具的情况下都能提供可靠的分割结果。
- 当手术场景光线良好且工具运动质量较高时,SAM 2 的分割效果最佳。
结论
讨论:
- 模型性能表现:
- SAM 2 在零样本视频分割任务中展示了显著的性能优势,尤其是在光线条件良好、工具运动质量高的情况下,能够准确分割手术视频中的工具。
- 在多种手术场景(如内镜手术和显微手术)中,SAM 2 通过仅在视频的第一帧提供点提示,就能生成可靠的工具分割结果,显示出其强大的通用性和适应能力。
- 模型的局限性:
- 长视频序列的分割挑战:随着视频序列的延长,SAM 2 的分割精度有所下降,尤其是在视频的后期阶段,细节分割的准确性降低。这种性能衰减对实时手术视频的应用是一个重大挑战,需要进一步改进。
- 复杂手术环境的影响:手术环境中的复杂因素,如模糊、出血和工具的遮挡,显著影响了SAM 2 的分割精度。特别是显微手术中,由于显微镜相机的限制和工具与手术表面的交互,模型容易失去分割的精细度。
- 应对策略:
- 引入额外的提示(如新的工具进入场景时),可以在一定程度上提高分割的准确性,尤其是在处理复杂或动态变化的手术场景时。
- 针对这些挑战,未来的研究方向应着重于如何改进模型在长视频序列中的表现,以及如何通过微调模型来增强其在复杂环境中的鲁棒性。
结论:
- SAM 2 作为第二代Segment Anything Model,在外科手术视频中的应用表现出色,特别是在零样本条件下,能够有效分割视频中的外科工具。其强大的通用性和在多种手术场景中的适应性,使其成为未来手术视频分析和实时辅助工具的有力候选者。
- 尽管SAM 2 在手术工具分割任务中展示了显著的性能提升,但其在长视频处理和复杂手术环境中的局限性仍需进一步研究。未来的工作应侧重于优化模型,以确保其在各种临床环境中具有更高的实用性和可靠性。
- 总体而言,本研究首次评估了SAM 2 在外科手术视频中的应用潜力,证明了其在多种手术场景下的有效性,并为未来手术AI系统的开发奠定了基础。研究结果为SAM 2 在临床实践中的应用提供了重要参考,特别是在提高手术精度和安全性方面。













{kind=link}