
根据单张图像和音频输入生成唱歌和说话视频,并能控制人物表情和姿态的模型 Hallo 发布了更新版本Hallo 2.
Hallo2 解决了长时、高分辨率的视频生成问题。它在现有的短时视频生成模型(如 Hallo)基础上进行了多项重要改进,能够生成长达一小时的4K分辨率人像视频,适用于各种人像表情和风格控制。
- 生成视频时长:最多支持生成 1小时 的连续人像视频,且保持视觉一致性。
- 分辨率支持:最高支持 4K分辨率 视频输出,生成的人像动画在细节和清晰度方面表现出色。
- 表情和风格控制:通过语音和文本标签的结合,生成的内容表现出高水平的可控性,能够根据不同输入生成情感丰富的多样化内容。
- 视觉一致性与时间连贯性:实验表明,Hallo2 通过补丁丢弃和噪声增强技术,在生成长时视频时极大程度上减少了表情抖动和外观漂移等问题。
Hallo2 是目前首个实现长达一小时、4K分辨率的音频驱动人像动画生成模型。通过创新的补丁丢弃、噪声增强和时间对齐等技术,它解决了长时视频生成中的外观漂移和视觉不一致问题,支持灵活的语音与文本控制,生成质量达到业内领先水平。
主要技术改进与功能
- 长时视频生成
- 传统的视频生成方法通常只适用于短时视频(几秒到几分钟),而长时生成会面临外观漂移(即生成的视频中的人物形象与开始不一致)和时间一致性丧失(如表情不连贯或抖动等)的问题。
- Hallo2 通过创新的条件运动帧增强策略解决了这些问题。具体来说,模型引入了补丁丢弃技术(patch-drop technique),结合高斯噪声增强,来保证视频在长时间生成中的视觉一致性和时间连贯性。
- 高分辨率视频生成
- 生成高清画面也是一个重大挑战,尤其是在4K分辨率下,细节和清晰度要求很高。为了解决这个问题,Hallo2 对潜在空间中的编码进行了矢量量化(vector quantization),同时使用时间对齐技术,确保视频在时间维度上保持一致。
- 最终,Hallo2 能够生成高达4K分辨率的高质量人像视频,细节和清晰度得到了显著提升。
- 多样化的风格控制与表情生成
- 在传统的音频驱动之外,Hallo2 增加了语义文本标签作为条件输入。这意味着用户不仅可以通过音频控制视频中的人物表情,还可以通过文本输入控制人物的风格和情感表现。
- 这一功能使得生成的内容更具多样性,能够根据不同的音频和文本提示生成不同风格的人像视频。例如,你可以生成开心、愤怒、忧郁等不同情感下的人像动画。
- 视觉一致性与时间连贯性
- 在长时视频生成中,保持人物外观和表情的一致性是一大挑战。为此,Hallo2 引入了补丁丢弃和高斯噪声增强的技术,增强了视觉的一致性。通过这些增强技术,模型能够在时间轴上保持较高的连贯性,避免了人物在视频中的不自然变化或突兀过渡。
- 这种技术还确保了视频在长时间播放过程中不会出现视觉上的不连贯现象。
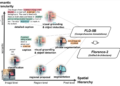
技术方法

1. 长时动画生成
问题:长时间生成视频时,常会出现外观漂移(即随着时间推移,生成的视频中人物的外观与最初的参考图像逐渐不同)以及时间一致性问题(即动作不连贯、抖动等现象)。
解决方案:
- 补丁丢弃技术(Patch Drop Technique):该技术通过随机丢弃之前生成的视频帧中的部分外观信息,仅保留与运动相关的动态信息。这种方式确保模型主要依赖参考图像的外观特征,减少了前后帧之间外观信息的干扰,从而保持视觉一致性。
- 每个帧被划分为多个不重叠的补丁,随机丢弃部分补丁以减弱外观信息的影响,保留与运动相关的空间结构。
- 高斯噪声增强:在生成的运动帧中引入高斯噪声,增强模型恢复原始外观和动态的能力,防止噪声和失真随时间累积。这一过程有助于保持长时间视频的视觉一致性。
2. 高分辨率增强(4K分辨率)
问题:在生成高分辨率视频时,生成的每一帧需要保持细节,同时跨时间轴保持一致性。
解决方案:
- 向量量化与时间对齐技术:Hallo2 通过向量量化生成视频帧的离散编码,并引入了时间对齐机制,确保不同帧之间在时间维度上的连贯性。具体做法包括:
- 空间自注意力(Spatial Self-Attention):确保每一帧的视觉细节通过查询、键和值的计算得到一致的处理,保持帧内的细节一致性。
- 时间对齐注意力(Temporal Alignment Attention):通过时间维度上的注意力机制,确保不同时间点的帧在运动和外观上保持连贯。
3. 文本标签控制
特点:为了增强生成动画的多样性和控制性,Hallo2 支持通过文本标签控制人物的表情、动作等细节。这一功能使得生成的内容可以根据用户输入的文本进行微调,例如生成不同情感或风格的动画。
具体做法:
- 语义文本标签:模型通过 CLIP 编码获取文本的语义信息,并通过可调的层归一化机制,将文本信息与图像生成过程结合。通过这种方式,文本标签可以直接影响生成图像的表情和姿态变化。
4. 网络架构与训练策略
网络架构:
- Denoising U-Net:用于去噪的U-Net架构是该模型的核心,处理每个时刻的噪声潜在向量。通过跨注意力层和音频、文本的结合,生成与音频同步、表情生动的动画帧。
训练策略:
- 两阶段训练:第一阶段模型生成视频帧,第二阶段引入补丁丢弃和高斯噪声增强技术,进一步训练模型生成长时视频的能力。
- 第一阶段重点训练空间交叉注意力模块,以提升模型生成能力。
- 第二阶段则重点处理时间一致性问题,通过运动帧的噪声增强和文本标签的引入,实现高质量的长时动画生成。
5. 数据增强与消融实验
数据增强:
- 补丁丢弃与高斯噪声增强:这两种增强策略结合使用,显著提升了生成视频的视觉一致性和表情连贯性。
消融实验:
- 实验结果表明,单独使用补丁丢弃或高斯噪声增强都能改善生成质量,但两者结合使用时效果最佳,能够显著降低FVD(视频视觉质量)和FID(图像视觉质量)等指标。
项目地址及更多演示:https://fudan-generative-vision.github.io/hallo2
- 论文:arXiv 论文
- 代码:GitHub 源代码
- 演示视频:HuggingFace
Hallo 1 介绍














{kind=link}