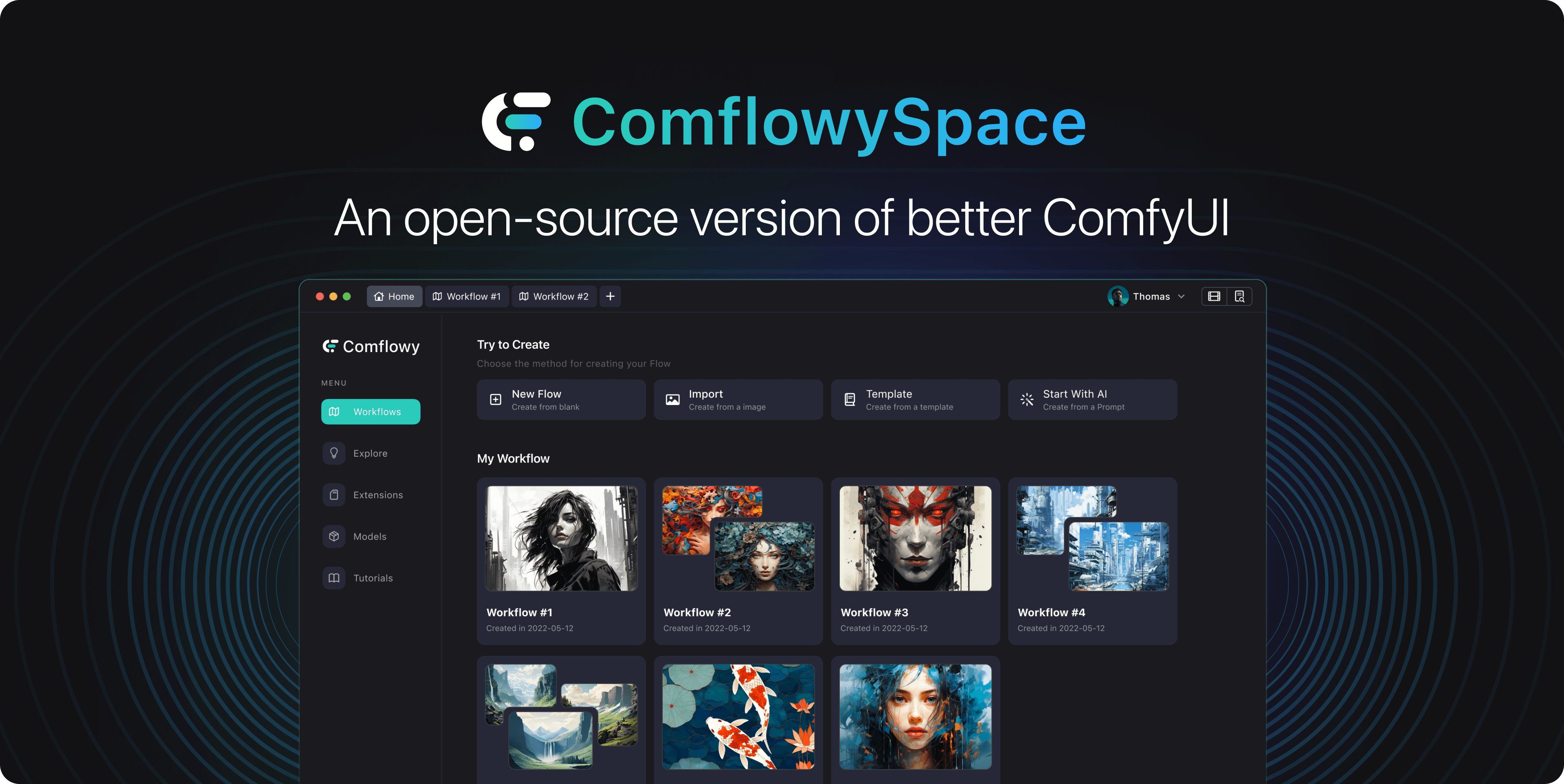
Comflowyspace是一个用于生成AI图像和视频的开源工具,它比现有的SDWebUI和ComfyUI更易用、交互性更强。 它旨在让那些因为技术门槛感到困惑的人们能够轻松地接触和使用AI生成技术。 Comflowyspace的设计目的是让每个人都能够简单地使用ComfyUI和Stable Diffusion,涵盖了从最初的下载安装到后续的插件管理、设置工作流程模板和编辑过程等各个方面,确保了操作的简便性。简而言之,Comflowyspace让AI创作变得对任何人都容易上手。 <img class=" wp-image-1554 aligncenter" src="https://img.xiaohu.ai/2024/03/editor-1024x728.jpg" alt="" width="773" height="549" /> <h3>功能特点:</h3> <ul> <li data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d"><strong data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d">更便捷的安装</strong>:解决了安装ComfyUI复杂且容易遇到各种问题导致安装失败的问题,提供一键安装功能,使用户可以在几分钟内完成安装。</li> <li data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d"><strong data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d">更高效的使用</strong>:提供了工作流管理功能,用户可以查看所有历史工作流,无需手动导出和保存工作流。此外,还提供了多标签功能,允许同时打开和运行多个工作流,提高了多任务处理的效率。</li> <li data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d"><strong data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d">更简单的设置</strong>:用户可以使用各种模板构建工作流,使得工作流的构建更加简单方便。</li> <li data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d"><strong data-immersive-translate-walked="ed6b6d65-ec20-4a72-903d-32d3f017165d">更友好的用户体验</strong>:优化了许多细节体验,使使用过程更加流畅。同时,Comflowyspace整合了教程,降低学习门槛。</li> </ul> <img class="wp-image-1553 aligncenter" src="https://img.xiaohu.ai/2024/03/home-1024x728.jpg" alt="" width="777" height="552" /> <img class="wp-image-1552 aligncenter" src="https://img.xiaohu.ai/2024/03/gallery-1024x728.jpg" alt="" width="771" height="548" /> GitHub:<a href="https://github.com/6174/comflowyspace" target="_blank" rel="noopener">https://github.com/6174/comflowyspace</a> <h3><strong>官网还可以有很多推荐模型下载</strong></h3> <img class=" wp-image-1556 aligncenter" src="https://img.xiaohu.ai/2024/03/下载-506x1024.jpeg" alt="" width="652" height="1320" /> 官网:<a href="https://www.comflowy.com/model" target="_blank" rel="noopener">https://www.comflowy.com/model</a>







{kind=link}