
Reka AI推出了其最大、最强大的多模态语言模型——Reka Core。Core能够处理文本、图像、视频和音频输入。该模型在数月内利用数千个GPU从零开始高效训练。
各种性能测试显示,在 MMMU 方面,Core 可与 GPT-4V 相媲美;在由独立第三方进行的多模态人类评估中,Core 优于 Claude-3 Opus;在视频任务方面,Core 超越了 Gemini Ultra。在语言任务方面,Core 在成熟的基准测试中可与其他前沿模型媲美。
Reka提供三种不同规模的模型——Reka Core, Flash和Edge,以满足不同的业务需求。
- Edge:7B 轻量级/本地模型
- Flash:21B,速度快,功能强
- Core:最大的模型,能胜任复杂任务
所有模型都是多模态的
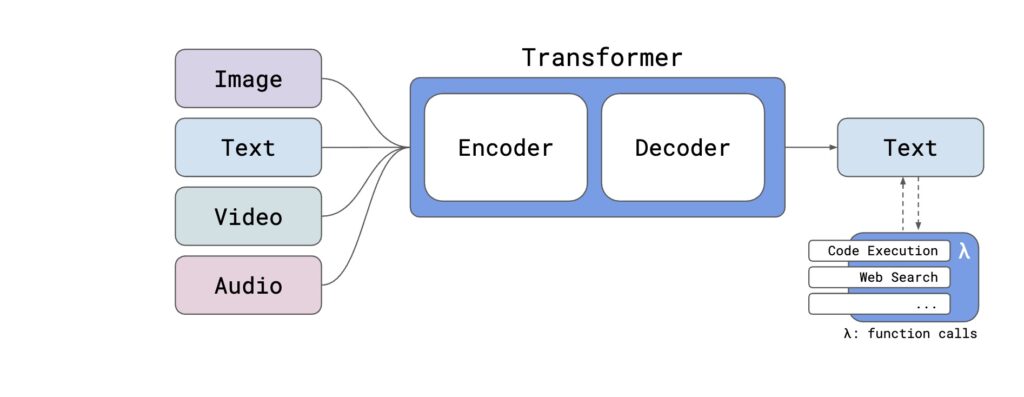
模型架构
Reka 模型系列(Reka Core, Reka Flash, 和 Reka Edge)基于广泛使用的 Transformer 架构变种之一,称为 Noam 架构,该架构通过自注意力(Self-attention)机制处理序列数据。采用的是一个模块化的编码器-解码器架构,这一架构支持多模态输入,如图像、文本、视频和音频。
模型基于以下几个核心技术构建:
- SwiGLU:一种激活函数,用于提高模型训练过程中的效率和效果。
- 分组查询注意力(Grouped Query Attention):这是一种优化的注意力机制,可以提高处理多种输入类型时的性能。
- 旋转位置嵌入(Rotary Positional Embeddings):增强模型对序列位置的敏感度,改善长文本和多模态数据的处理能力。
- RMSNorm:一种归一化技术,有助于模型在训练过程中的稳定性。
此外,这些模型使用基于句子片段(sentencepiece)的词汇表,并且在训练中加入了特殊的标记(如 <extra_id_0>)以支持更复杂的任务处理。
Reka Core的主要能力
Reka Core是一个前沿的多模态语言模型,具备以下核心能力:
-
多模态理解:
- Reka 模型能处理包括文本、图像、视频和音频在内的多种数据类型,使其能够在多种应用场景中发挥作用,例如自动内容生成、多媒体信息检索和高级交互系统。
- 它是市场上少数能够全面处理多种模态输入的解决方案之一。
-
128K上下文窗口:
- Reka Core 和 Reka Flash 模型具备高达 128K 的上下文窗口,使其能够处理和理解大量的输入数据,适合需要长文本理解和记忆的应用。
- 该模型能够摄取并精确、准确地回忆大量信息,极大地扩展了处理复杂文档和数据流的能力。
-
推理能力:
- Reka Core在语言和数学方面具有出色的推理能力,适合执行需要复杂分析和推理的任务。
-
高级推理和编码能力:
- 模型不仅在语言理解方面表现出色,还具备进行复杂推理和编码的能力,可以支持复杂的代理工作流,自动化各种复杂的工作任务。
-
多语言能力:
- 模型在预训练阶段处理了包括中文、日文、法文、韩文和西班牙文在内的 32 种语言,具备强大的跨语言处理能力。
-
部署灵活性:
- Reka Core支持多种部署选项,包括通过API、现场部署或设备上部署,以满足不同客户和合作伙伴的具体需求。
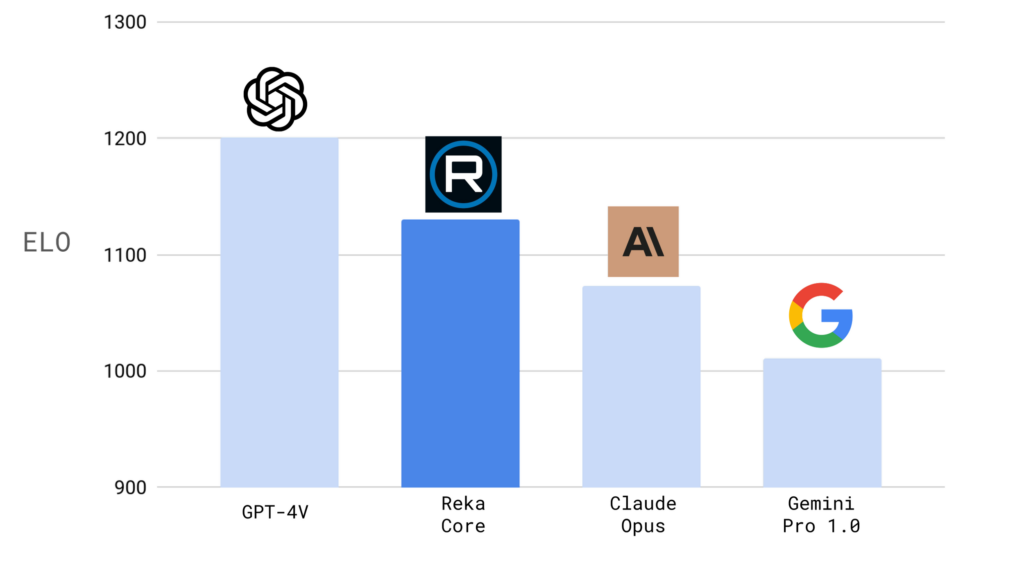
性能表现
- Reka Core 在自动化评估和盲测试的人类评价中均表现出色,其性能接近或优于业界顶尖模型,如 OpenAI 的 GPT-4V 和 Google 的 Gemini Ultra。
- 在特定的基准测试中,如图像问答(MMMU, VQAv2)和视频问答任务,Reka Core 的表现超过了多个竞争模型。
- Reka Edge 和 Flash 虽然参数量较少,但在它们的计算类别中常常超越更大的模型,提供了超常的价值。
-
多模态任务性能:
- 图像问答:Reka Core 在图像问答基准(如 MMMU 和 VQA v2)中展现了竞争力,与当前最先进的模型(如 GPT-4V 和 Claude 3)相比具有可比性。
- 视频问答:在 Perception-Test 基准上,Reka Flash 和 Reka Core 显著超过了同类模型如 Gemini Ultra,显示了其在理解和回答基于视频内容的问题上的优势。
- 多模态交流:在多模态聊天的盲评中,Reka Core 在人类评估中排名靠前,显示了其在处理图像和文本结合的交互任务中的能力。
-
语言处理任务性能:
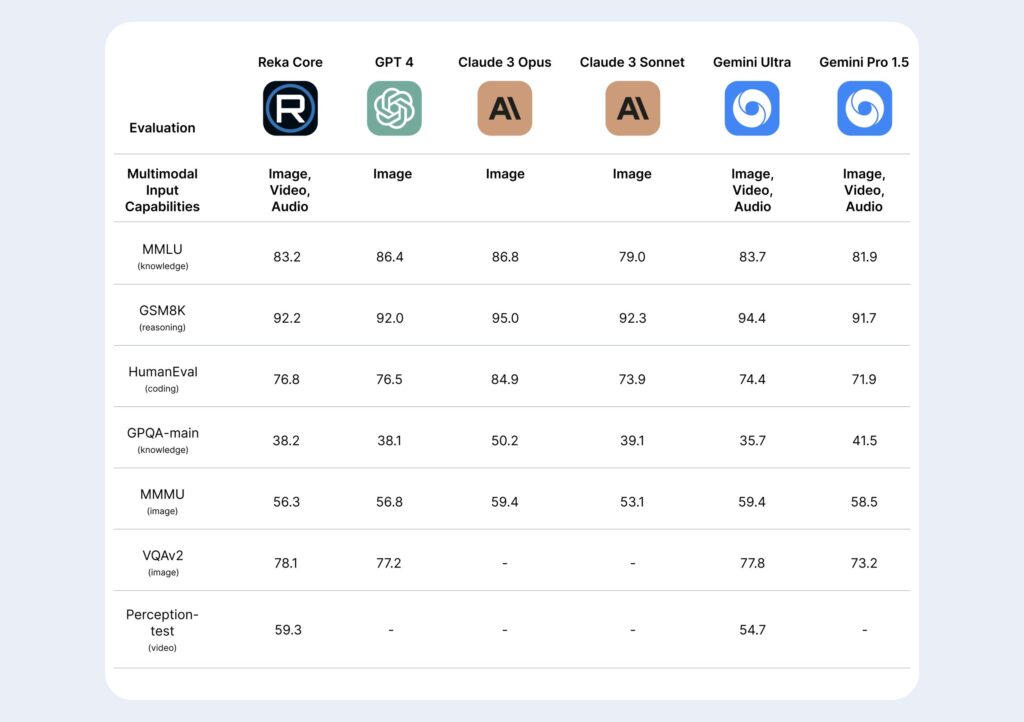
- 语言基准测试:Reka Core 在广泛的语言理解和问答任务(如 MMLU, GSM8K 和 HumanEval)中与前沿模型竞争,甚至在某些指标上超过了 GPT-4。
- 长文本处理:在长文本问答任务中,Reka Core 和 Reka Flash 处理能力强,能够有效地处理并回答基于长文档的问题,这在法律和科技领域的应用中尤为重要。
-
基准评估和人类评价:
- 盲人评估:在第三方盲人评估中,Reka Core 在多模态和纯文本聊天任务中都表现出色,证明了其在自然语言理解和生成方面的能力。
- ELO 评分系统:在使用 ELO 评分系统的比较中,Reka Core 在多模态和纯文本聊天设置中通常胜过其他模型,如 Claude 3 和 Gemini Pro。
-
多语言和跨语言任务:
- 多语言性能:Reka 模型显示了在处理多种语言的能力,这得益于其训练数据的多样性和包容性,使其在全球多语言应用中具有实际的应用潜力。
-
特定领域的应用:
- 医学推理:在专门的医学推理任务中,Reka Core 和 Reka Flash 显示出与领域特化模型(如 Meditron 和 Med-PaLM-2)竞争的性能,特别是在 MedMCQA 和 PubMedQA 基准上。
Reka API 定价
Reka AI 提供了一系列多模态模型的 API 接入服务,这些服务旨在支持企业和开发者轻松部署和使用 Reka 的高级模型。以下是 Reka API 的主要信息:
模型及定价:
- Reka Core:适用于复杂任务的高级模型,定价为每百万输入令牌 $10,每百万输出令牌 $25。
- Reka Flash:快速且成本效益高的模型,适合大多数任务,定价为每百万输入令牌 $0.8,每百万输出令牌 $2。
- Reka Edge:轻量级模型,适用于本地或对延迟敏感的应用,定价为每百万输入令牌 $0.4,每百万输出令牌 $1。
部署选项:
- On-Device:Reka Edge 可以高效地部署在各种设备上。
- On-Premise:Reka 模型是少数可以安全部署并可在本地扩展的商业解决方案之一。
一些案例
这是什么动物?


这张照片是在哪里拍摄的?


哪个股票代码在投资组合中的权重最高?

 根据绿色标志,最左侧的两条车道通往哪些城市?
根据绿色标志,最左侧的两条车道通往哪些城市?


这里有多少乐队成员?每个人在演奏什么吗?从左到右,列举出他们使用的乐器

视频演示:
关于 Reka AI
公司简介: Reka AI 是一家全球性的基础模型初创企业,总部位于加利福尼亚州的森尼维尔,采用远程优先的工作模式,团队成员遍布加利福尼亚、西雅图、伦敦、苏黎世、香港和新加坡等地。Reka AI 的使命是构建有用的多模态人工智能技术,并利用这些技术赋能各种组织和企业。
团队背景: Reka AI 的创始团队由来自 DeepMind、Google Brain 和 FAIR 的研究科学家和工程师组成。这个团队在过去十年中为 AI 领域的多项突破性成就作出了贡献。
核心团队成员:
- Dani Yogatama:CEO & Co-Founder,前 DeepMind 员工(2016-2022),博士(2015年获得)。Dani Yogatama:CEO & Co-Founder,前 DeepMind 员工(2016-2022),博士(2015年获得)。
- Yi Tay:首席科学家 & Co-Founder,前 Google Brain 员工(2019-2023),博士(2019年获得)。
- Mikel Artetxe:Co-Founder,前 FAIR 员工(2020-2023),博士(2020年获得)。
- Cyprien de Masson d’Autume:CTO & Co-Founder,前 DeepMind 员工。Cyprien de Masson d’Autume:CTO & Co-Founder,前 DeepMind 员工。
- Qi Liu:Co-Founder,前 FAIR 和 DeepMind 员工,博士(2022年获得)。
介绍:https://www.reka.ai/news/reka-core-our-frontier-class-multimodal-language-model















{kind=link}