
马克斯·普朗克信息学研究所、萨尔大学和萨尔布吕肯视觉计算、交互与人工智能研究中心合作,提出了一种新的实时渲染方法。它只需要4个摄像头视角和3D骨骼姿势,即可捕捉到人类运动的细节,包括衣服褶皱、面部表情和手势。同时可以实时以4K分辨率呈现人类的高度逼真的自由视角视频。
主要功能包括:
-
实时自由视角呈现: 仅需4个稀疏摄像头视角和3D骨骼姿势数据,即可在4K分辨率下实时生成角色的自由视角视频。
-
高精度动态建模: 利用骨骼驱动的神经网络精确捕捉人体的动态几何形状,呈现衣物褶皱、面部表情和手势等细节。
-
依视角变化的纹理映射: 从4个摄像头视角创建依视角而变的纹理,准确重现角色的动态纹理细节。
-
图像优化与4K渲染: 基于图像的优化网络生成高分辨率的最终视频画面,确保呈现效果逼真和细腻。
-
广泛适用的角色表现: 无论演员穿着紧身或宽松服装,该方法都能适应并呈现出真实的细节,适用于各种表演和动作。通过对动态角色网格的建模、纹理映射及图像优化,准确捕捉角色的各类动态细节。适用于动画制作、影视特效以及游戏开发。也可将虚拟角色放入各种场景,实现逼真的沉浸式交互体验。
技术方法
主要技术方法可以简单理解为:
-
骨骼模型驱动: 通过使用人的骨骼姿势数据,计算机会创建一个跟踪人体运动的虚拟模型。
-
多角度纹理映射: 从不同角度的摄像头视角,将捕捉到的图像映射到虚拟模型上,让模型呈现逼真的外观。
-
纹理增强: 使用神经网络进行纹理处理,将多角度的图像数据结合起来,生成细节丰富的纹理效果,比如衣服的褶皱和面部表情。
-
图像优化: 最终,模型会被渲染成4K的超高分辨率画面,确保虚拟角色在画面中看起来细腻、真实,甚至可以处理复杂的服装或姿势。
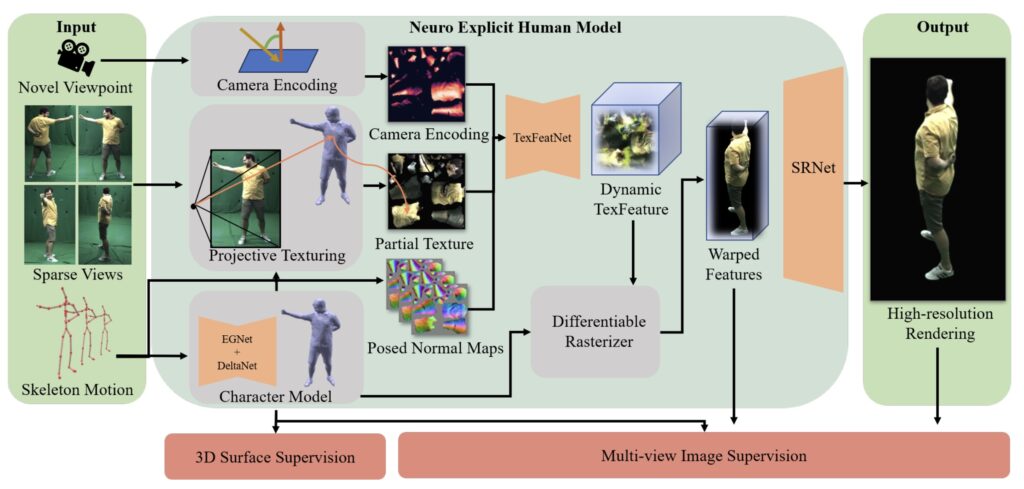
详细介绍
-
骨骼驱动的可变形模型: 使用骨骼驱动的神经网络,基于演员的3D骨骼姿势和4个摄像头的多视角视频输入,创建详细的动态网格模型。该模型包括:
- 粗略变形: 利用图神经网络预测嵌入图节点的旋转和位移,以进行粗略的几何变形。
- 精细变形: 利用第二个网络预测每个顶点的位移,确保模型捕捉更精细的动态几何细节。
-
依视角变化的纹理映射: 将多视角输入投影到角色网格的纹理空间,通过可见性和投影角�
















{kind=link}